No Graphics API
Introduction
The complexity of graphics APIs, shader frameworks and drivers have increased rapidly during the past decades. The pipeline state object (PSO) explosion has gotten out of hands. How did we end up with 100GB local shader pipeline caches and massive cloud servers to host them? It’s time to start discussing how to cut down the abstractions and the API surface to simplify how we interact with the GPU.
This blog post includes lots of low level hardware details. When writing this post I used “GPT5 Thinking” AI model to cross reference public Linux open source drivers to confirm my knowledge and to ensure no NDA information is present in this blog post. Sources: AMD RDNA ISA documents and GPUOpen, Nvidia PTX ISA documents, Intel PRM, Linux open source GPU drivers (Mesa, Freedreno, Turnip, Asahi) and vendor optimization guides/presentations. The blog post has been screened by several industry insiders before the public release.
Low-level graphics APIs change the industry
Ten years ago, a significant shift occurred in real-time computer graphics with the introduction of new low-level PC graphics APIs. AMD had won both Xbox One (2013) and Playstation 4 (2013) contracts. Their new Graphics Core Next (GCN) architecture became the de-facto lead development platform for AAA games. PC graphics APIs at that time, DirectX 11 and OpenGL 4.5, had heavy driver overhead and were designed for single threaded rendering. AAA developers demanded higher performance APIs for PC. DICE joined with AMD to create a low level AMD GCN specific API for the PC called Mantle. As a response, Microsoft, Khronos and Apple started developing their own low-level APIs: DirectX 12, Vulkan and Metal were born.
The initial reception of these new low-level APIs was mixed. Synthetic benchmarks and demos showed substantial performance increases, but performance gains couldn’t be seen in major game engines such as Unreal and Unity. At Ubisoft, our teams noticed that porting existing DirectX 11 renderers to DirectX 12 often resulted in performance regression. Something wasn’t right.
Existing high-level APIs featured minimal persistent state, with fine-grained state setters and individual data inputs bound to the shader just prior to draw call submission. New low-level APIs aimed to make draw calls cheaper by ahead-of-time bundling shader pipeline state and bindings into persistent objects. GPU architectures were highly heterogeneous back in the day. Doing the data remapping, validation, and uploading ahead of time was a big gain. However, the rendering hardware interfaces (RHI) of existing game engines were designed for fine grained immediate mode rendering, while the new low-level APIs required bundling data in persistent objects.
To address this incompatibility, a new low-level graphics remapping layer grew beneath the RHI. This layer assumed the complexity previously handled by the OpenGL and DirectX 11 graphics drivers, tracking resources and managing mappings between the fine-grained dynamic user-land state and the persistent low-level GPU state. Graphics programmers started specializing into two distinct roles: low-level graphics programmers, who focused on the new low-level “driver” layer and the RHI, and high-level graphics programmers, who built visual graphics algorithms on top of the RHI. Visual programming was also getting more complex due to physically based lighting models, compute shaders and later ray-tracing.
Modern APIs?
DirectX 12, Vulkan, and Metal are often referred to as “modern APIs”. These APIs are now 10 years old. They were initially designed to support GPUs that are now 13 years old, an incredibly long time in GPU history. Older GPU architectures were optimized for traditional vertex and pixel shader tasks rather than the compute-intensive generic workloads prevalent today. They had vendor specific binding models and data paths. Hardware differences had to be wrapped under the same API. Ahead-of-time created persistent objects were crucial in offloading the mapping, uploading, validation and binding costs.
In contrast, the console APIs and Mantle were exclusively designed for AMD's GCN architecture, a forward-thinking design for its time. GCN boasted a comprehensive read/write cache hierarchy and scalar registers capable of storing texture and buffer descriptors, effectively treating everything as memory. No complex API for remapping the data was required, and significantly less ahead-of-time work was needed. The console APIs and Mantle had much less API complexity due to targeting a single modern GPU architecture.
A decade has passed, and GPUs have undergone a significant evolution. All modern GPU architectures now feature complete cache hierarchies with coherent last-level caches. CPUs can write directly to GPU memory using PCIe REBAR or UMA and 64-bit GPU pointers are directly supported in shaders. Texture samplers are bindless, eliminating the need for a CPU driver to configure the descriptor bindings. Texture descriptors can be directly stored in arrays within the GPU memory (often called descriptor heaps). If we were to design an API tailored for modern GPUs today, it wouldn’t need most of these persistent “retained mode” objects. The compromises that DirectX 12.0, Metal 1 and Vulkan 1.0 had to make are not needed anymore. We could simplify the API drastically.
The past decade has revealed the weaknesses of the modern APIs. The PSO permutation explosion is the biggest problem we need to solve. Vendors (Valve, Nvidia, etc) have massive cloud servers storing terabytes of PSOs for each different architecture/driver combination. User's local PSO cache size can exceed 100GB. No wonder the gamers are complaining that loading takes ages and stutter is all over the place.
The history of GPUs and APIs
Before we talk about stripping the API surface, we need to understand why graphics APIs were historically designed this way. OpenGL wasn't intentionally slow, nor was Vulkan intentionally complex. 10-20 years ago GPU hardware was highly diverse and undergoing rapid evolution. Designing a cross-platform API for such a diverse set of hardware required compromises.
Let’s start with a classic: The 3dFX Voodoo 2 12MB (1998) was a three chip design: A single rasterizer chip connected to a 4MB framebuffer memory and two texture sampling chips, each connected to their own 4MB texture memory. There was no geometry pipeline and no programmable shaders. CPU sent pre-transformed triangle vertices to the rasterizer. The rasterizer had a configurable blending equation to control how the vertex colors and the two texture sampler results were combined together. Texture samplers could not read each-other’s memory or the framebuffer. Thus there was no support for multiple render passes. Since the hardware was incapable of window composition, it had a loopback cable to connect your dedicated 2d video card. 3d rendering only worked in exclusive fullscreen mode. A 3d graphics card was a highly specialized piece of hardware, with little in common with the current GPUs and their massive programmable SIMD arrays. Hardware of this era had a massive impact on DirectX (1995) and OpenGL (1992) design. Backwards compatibility played a huge role. APIs improved iteratively. These 30 year old API designs still impact the way we write software today.

3dFX Voodoo 2 12MB (1998): Individual processors and traces between them and their own memory chips (four 1MB chips for each processor) are clearly visible. Image © TechPowerUp.
Nvidia’s Geforce 256 coined the term GPU. It had a geometry processor in addition to the rasterizer. The geometry processor, rasterizer and texture sampling units were all integrated in the same die and shared memory. DirectX 7 introduced two new concepts: render target textures and uniform constants. Multipass rendering meant that texture samplers could read the rasterizer output, invalidating the 3dFX Voodoo 2 separate memory design.
The geometry processor API featured uniform data inputs for transform matrices (float4x4), light positions, and colors (float4). GPU implementations varied among manufacturers, many opting to embed a small constant memory block within the geometry engine. But this wasn’t the only way to do it. In the OpenGL API each shader had its own persistent uniforms. This design enabled the driver to embed constants directly in the shader's instruction stream, an API peculiarity that still persists in OpenGL 4.6 and ES 3.2 today.
GPUs back then didn’t have generic read & write caches. Rasterizer had screen local cache for blending and depth buffering and texture samplers leaned on linearly interpolated vertex UVs for data prefetching. When shaders were introduced in DirectX 8 shader model 1.0 (SM 1.0), the pixel shader stage didn’t support calculating texture UVs. UVs were calculated at vertex granularity, interpolated by the hardware and passed directly to the texture samplers.
DirectX 9 brought a substantial increase in shader instruction limits, but shader model 2.0 didn’t expose any new data paths. Both vertex and pixel shaders still operated as 1:1 input:output machines, allowing users to only customize the transform math of the vertex position and attributes and the pixel color. Programmable load and store were not supported. The fixed-function input blocks persisted: vertex fetch, uniform (constant) memory and texture sampler. Vertex shader was a separate execution unit. It gained new features like the ability to index constants (limited to float4 arrays) but still lacked texture sampling support.
DirectX 9 shader model 3.0 increased the instruction limit to 65536 making it difficult for humans to write and maintain shader assembly anymore. Higher level shading languages were born: HLSL (2002) and GLSL (2002-2004). These languages adapted the 1:1 elementwise transform design. Each shader invocation operated on a single data element: vertex or pixel. Framework-style shader design heavily affected the graphics API design in the following years. It was a nice way to abstract hardware differences back in the day, but is showing scaling pains today.
DirectX 11 was a significant shift in the data model, introducing support for compute shaders, generic read-write buffers and indirect drawing. The GPU could now fully feed itself. The inclusion of generic buffers enabled shader programs to access and modify programmable memory locations, which forced hardware vendors to implement generic cache hierarchies. Shaders evolved beyond simple 1:1 data transformations, marking the end of specialized, hardcoded data paths. GPU hardware started to shift towards a generic SIMD design. SIMD units were now executing all the different shader types: vertex, pixel, geometry, hull, domain and compute. Today the framework has 16 different shader entry points. This adds a lot of API surface and makes composition difficult. As a result GLSL and HLSL still don’t have a flourishing library ecosystem.
DirectX 11 featured a whole zoo of buffer types, each designed to accommodate specific hardware data path peculiarities: typed SRV & UAV, byte address SRV & UAV, structured SRV & UAV, append & consume (with counter), constant, vertex, and index buffers. Like textures, buffers in DirectX utilize an opaque descriptor. Descriptors are hardware specific (commonly 128-256 bit) data blobs encoding the size, format, properties and data address of the resource in GPU memory. DirectX 11 GPUs leveraged their texture samplers for buffer load (gather) operations. This was natural since the sampler already had a type conversion hardware and a small read-only data cache. Typed buffers supported the same formats as textures, and DirectX used the same SRV (shader resource view) abstraction for both textures and buffers.
The use of opaque buffer descriptors meant that the buffer format was not known at shader compile time. This was fine for read-only buffers as they were handled by the texture sampler. Read-write buffer (UAV in DirectX) was initially limited to 32-bit and 128-bit (vec4) types. Subsequent API and hardware revisions gradually addressed typed UAV load limitations, but the core issues persisted: a descriptor requires an indirection (contains a pointer), compiler optimizations are limited (data type is known only at runtime), format conversion hardware introduces latency (vs raw L1$ load), expand at load reserves registers for longer time (vs expand at use), descriptor management adds CPU driver complexity, and the API is complex (ten different buffer types).
In DirectX 11 the structured buffers were the only buffer type allowing an user defined struct type. All other buffer types represented a homogeneous array of simple scalar/vector elements. Unfortunately, structured buffers were not layout compatible with other buffer types. Users were not allowed to have structured buffer views to typed buffers, byte address buffers, or vertex/index buffers. The reason was that structured buffers had special AoSoA swizzle optimization under the hood, which was important for older vec4 architectures. This hardware specific optimization limited the structured buffer usability.
DirectX 12 made all buffers linear in memory, making them compatible with each other. SM 6.2 also added load<T> syntactic sugar for the byte address buffer, allowing clean struct loading syntax from arbitrary offset. All the old buffer types are still supported for backwards compatibility reasons and all the buffers still use opaque descriptors. HLSL is still missing support for 64-bit GPU pointers. In contrast, the Nvidia CUDA computing platform (2007) fully leaned on 64-bit pointers, but its popularity was initially limited to academic use. Today it is the leading AI platform and is heavily affecting the hardware design.
Support for 16-bit registers and 16-bit math was disorganized when DirectX 12 launched. Microsoft initially made a questionable decision to not backport DirectX 12 to Windows 7. Shader binaries targeting Windows 8 supported 16-bit types, but most gamers continued using Windows 7. Developers didn’t want to ship two sets of shaders. OpenGL lowp/mediump specification was also messy. Bit depths were not properly standardized. Mediump was a popular optimization in mobile games, but most PC drivers ignored it, making game developer’s life miserable. AAA games mostly ignored 16-bit math until PS4 Pro launched in 2016 with double rate fp16 support.
With the rise of AI, ray-tracing, and GPU-driven rendering, GPU vendors started focusing on optimizing their raw data load paths and providing larger and faster generic caches. Routing loads though the texture sampler (type conversion) added too much latency, as dependent load chains are common in modern shaders. Hardware got native support for narrow 8-bit, 16-bit, and 64-bit types and pointers.
Most vendors ditched their fixed function vertex fetch hardware, emitting standard raw load instructions in the vertex shader instead. Fully programmable vertex fetch allowed developers to write new algorithms such as clustered GPU-driven rendering. Fixed function hardware transistor budget could be used elsewhere.
Mesh shaders represent the culmination of rasterizer evolution, eliminating the need for index deduplication hardware and post-transform caches. In this paradigm, all inputs are treated as raw memory. The user is responsible for dividing the mesh into self-contained meshlets that internally share vertices. This process is often done offline. The GPU no longer needs to do parallel index deduplication for each draw call, saving power and transistors. Given that gaming accounts for only 10% of Nvidia's revenue today, while AI represents 90% and ray-tracing continues to grow, it is likely only a matter of time before the fixed function geometry hardware is stripped to bare minimum and drivers automatically convert vertex shaders to mesh shaders.
Mobile GPUs are tile-based renderers. Tilers bin the individual triangles to small tiles (commonly between 16x16 to 64x64 pixels) . Mesh shaders are too coarse grained for this purpose. Binning meshlets to tiny tiles would cause significant geometry overshading. There’s no clear convergence path. We still need to support the vertex shader path.
10 years ago when DirectX 12.0, Vulkan 1.0 and Metal 1.0 arrived, the existing GPU hardware didn’t widely support bindless resources. APIs adapted complex binding models to abstract the hardware differences. DirectX allowed indexing up to 128 resources per stage, Vulkan and Metal didn’t initially support descriptor indexing at all. Developers had to continue using traditional workarounds to reduce the bindings change overhead, such as packing textures into atlases and merging meshes together. The GPU hardware has evolved significantly during the past decade and converged to generic bindless SIMD design.
Let’s investigate how much simpler the graphics API and the shader language would become if we designed them solely for modern bindless hardware.
Modern GPU memory management
Let’s start our journey discussing memory management. Legacy graphics APIs abstracted the GPU memory management completely. Abstraction was necessary, as old GPUs had split memories and/or special data paths with various cache coherency concerns. When DirectX 12 and Vulkan arrived 10 years ago, the GPU hardware had matured enough to expose placement heaps to the user. Consoles had already exposed memory for a few generations and developers requested similar flexibility for PC and mobile. Apple introduced placement heaps 4 years after Vulkan and DirectX 12 in Metal 2.
Modern APIs require the user to enumerate the heap types to find out what kind of memory the GPU driver has to offer. It’s a good practice to preallocate memory in big chunks and suballocate it using a user-land allocator. However, there’s a design flaw in Vulkan: You have to create your texture/buffer object first. Then you can ask which heap types are compatible with the new resource. This forces the user into a lazy allocation pattern, which can cause performance hitches and memory spikes at runtime. This also makes it difficult to wrap a GPU memory allocation into a cross-platform library. AMD VMA, for example, creates both the Vulkan-specific buffer/texture object in addition to allocating memory. We want to fully separate these concerns.
Today the CPU has full visibility into the GPU memory. Integrated GPUs have UMA, and modern discrete GPUs have PCIe Resizable BAR. The whole GPU heap can be mapped. Vulkan heap API naturally supports CPU mapped GPU heaps. DirectX 12 got support in 2023 (HEAP_TYPE_GPU_UPLOAD).
CUDA has a simple design for GPU memory allocation: The GPU malloc API takes the size as input and returns a mapped CPU pointer. The GPU free API frees the memory. CUDA doesn’t support CPU mapped GPU memory. The GPU reads the CPU memory though the PCIe bus. CUDA also supports GPU memory allocations, but they can’t be directly written by the CPU.
We combine CUDA malloc design with CPU mapped GPU memory (UMA/ReBAR). It's the best of both worlds: The data is fast for the CPU to write and fast for the GPU to read, yet we maintain the clean, easy to use design.
// Allocate GPU memory for array of 1024 uint32
uint32* numbers = gpuMalloc(1024 * sizeof(uint32));
// Directly initialize (CPU mapped GPU pointer)
for (int i = 0; i < 1024; i++) numbers[i] = random();
gpuFree(numbers);Default gpuMalloc alignment is 16 bytes (vec4 alignment). If you need wider alignment use gpuMalloc(size, alignment) overload. My example code uses gpuMalloc<T> wrapper, doing gpuMalloc(elements * sizeof(T), alignof(T)).
Writing data directly into GPU memory is optimal for small data like draw arguments, uniforms and descriptors. For large persistent data, we still want to perform a copy operation. GPUs store textures in a swizzled layout similar to Morton-order to improve cache locality. DirectX 11.3 and 12 tried to standardize the swizzle layout, but couldn’t get all GPU manufacturers onboard. The common way to perform texture swizzling is to use a driver provided copy command. The copy command reads linear texture data from a CPU mapped “upload” heap and writes to a swizzled layout in a private GPU heap. Every modern GPU also has lossless delta color compression (DCC). Modern GPUs copy engines are capable of DCC compression and decompression. DCC and Morton swizzle are the main reasons we want to copy textures into a private GPU heap. Recently, GPUs have also added generic lossless memory compression for buffer data. If the memory heap is CPU mapped, the GPU can’t enable vendor specific lossless compression, as the CPU wouldn’t know how to read or write it. A copy command must be used to compress the data.
We need a memory type parameter in the GPU malloc function to add support for private GPU memory. The standard memory type should be CPU mapped GPU memory (write combined CPU access). It is fast for the GPU to read, and the CPU can directly write to it just like it was a CPU memory pointer. GPU-only memory is used for textures and big GPU-only buffers. The CPU can’t directly write to these GPU pointers. The user writes the data to CPU mapped GPU memory first and then issues a copy command, which transforms the data to optimal compressed format. Modern texture samplers and display engines can read compressed GPU data directly, so there’s no need for subsequent data layout transforms (see chapter: Modern barriers). The uploaded data is ready to use immediately.
We have two types of GPU pointers, a CPU mapped virtual address and a GPU virtual address. The GPU can only dereference GPU addresses. All pointers in GPU data structures must use GPU addresses. CPU mapped addresses are only used for CPU writes. CUDA has an API to transform a CPU mapped address to a GPU address (cudaHostGetDevicePointer). Metal 4 buffer object has two getters: .contents (CPU mapped address) and .gpuAddress (GPU address). Since the gpuMalloc API returns a pointer, not a managed object handle (like Metal), we choose the CUDA approach (gpuHostToDevicePointer). This API call is not free. The driver likely implements it using a hash map (if other than base addresses need to be translated, we need a tree). Preferably we call the address translation once per allocation and cache in a user land struct (void *cpu, void *gpu). This is the approach my userland GPUBumpAllocator uses (see appendix for full implementation).
// Load a mesh using a 3rd party library
auto mesh = createMesh("mesh.obj");
auto upload = uploadBumpAllocator.allocate(mesh.byteSize); // Custom bump allocator (wraps a gpuMalloc ptr)
mesh.load(upload.cpu);
// Allocate GPU-only memory and copy into it
void* meshGpu = gpuMalloc(mesh.byteSize, MEMORY_GPU);
gpuMemCpy(commandBuffer, meshGpu, upload.gpu);Vulkan recently got a new extension called VK_EXT_host_image_copy. The driver implements a direct CPU to GPU image copy operation, performing the hardware specific texture swizzle on CPU. This extension is currently only available on UMA architectures, but there’s no technical reason why it’s not available on PCIe ReBAR as well. Unfortunately this API doesn’t support DCC. It would be too expensive to perform DCC compression on the CPU. The extension is mainly useful for block compressed textures, as they don’t require DCC. It can’t universally replace hardware copy to GPU private memory.
There’s also a need for a third memory type, CPU-cached, for readback purposes. This memory type is slower for the GPU to write due to cache coherency with the CPU. Games only use readback seldomly. Common use cases are screenshots and virtual texturing readback. GPGPU algorithms such as AI training and inference lean on efficient communication between the CPU and the GPU.
When we mix the simplicity of CUDA malloc with CPU-mapped GPU memory we get a flexible and fast GPU memory allocation system with minimal API surface. This is an excellent starting point for a minimalistic modern graphics API.
Modern data
CUDA, Metal and OpenCL leverage C/C++ shader languages featuring 64-bit pointer semantics. These languages support loading and storing of structs from/to any appropriately aligned GPU memory location. The compiler handles behind-the-scenes optimizations, including wide loads (combine), register mappings, and bit extractions. Many modern GPUs offer free instruction modifiers for extracting 8/16-bit portions of a register, allowing the compiler to pack 8-bit and 16-bit values into a single register. This keeps the shader code clean and efficient.
If you load a struct of eight 32-bit values, the compiler will most likely emit two 128-bit wide loads (each filling 4 registers), a 4x reduction in load instruction count. Wide loads are significantly faster, especially if the struct contains narrow 8 and 16-bit fields. GPUs are ALU dense and have big register files, but compared to CPUs their memory paths are relatively slow. A CPU often has two load ports each doing a load per cycle. On a modern GPU we can achieve one SIMD load per 4 cycles. Wide load + unpack in the shader is often the most efficient way to handle data.
Compact 8-16 bit data has been traditionally stored in texel buffers (Buffer<T>) in DirectX games. Modern GPUs are optimized for compute workloads. Raw buffer load instructions nowadays have up to 2x higher throughput and up to 3x lower latency than texel buffers. Texel buffers are no longer the optimal choice on modern GPUs. Texel buffers do not support structured data, the user is forced to split their data into SoA layout in multiple texel buffers. Each texel buffer has its own descriptor, which must be loaded before the data can be accessed. This consumes resources (SGPRs, descriptor cache slots) and adds startup latency compared to using a single 64-bit raw pointer. SoA data layout also results in significantly more cache misses for non-linear index lookups (examples: material, texture, triangle, instance, bone id). Texel buffers offer free conversion of normalized ([0,1] and [-1,1]) types to floating point registers. It’s true that there’s no ALU cost, but you lose wide load support (combine loads) and the instruction goes through the slow texture sampler hardware path. Narrow texel buffer loads also add register bloat. RGBA8_UNORM load to vec4 allocates four vector registers immediately. The sampler hardware will eventually write the value to these registers. Compilers try to maximize the distance of load→use by moving load instructions in the beginning of the shader. This hides the load latency by ALU and allows overlapping multiple loads. If we instead use wide raw loads, our uint8x4 data consumes just a single 32-bit register. We unpack the 8-bit channels on use. The register life time is much shorter. Modern GPUs can directly access 16-bit low/high halves of registers without unpack, and some can even do 8-bit (AMD SDWA modifier). Packed double rate math makes 2x16 bit conversion instructions faster. Some GPU architectures (Nvidia, AMD) can also do 64-bit pointer raw loads directly from VRAM into groupshared memory, further reducing the register bloat needed for latency hiding. By using 64-bit pointers, game engines benefit from AI hardware optimizations.
Pointer based systems make memory alignment explicit. When you are allocating a buffer object in DirectX or Vulkan, you need to query the API for alignment. Buffer bind offsets must also be properly aligned. Vulkan has an API for querying the bind offset alignment and DirectX has fixed alignment rules. Alignment contract allows the low level shader compiler to emit optimal code (such as aligned 4x32-byte wide loads). The DirectX ByteAddressBuffer abstraction has a design flaw: load2, load3 and load4 instructions only require 4-byte alignment. The new SM 6.2 load<T> also only requires elementwise alignment (half4 = 2, float4 = 4). Some GPU vendors (like Nvidia) have to split ByteAddressBuffer.load4 into four individual load instructions. The buffer abstraction can’t always shield the user from bad codegen. It makes bad codegen hard to fix. C/C++ based languages (CUDA, Metal) allow the user to explicitly declare struct alignment with the alignas attribute. We use alignas(16) in all our example code root structs.
By default, GPU writes are only visible to the threads inside the same thread group (= inside a compute unit). This allows non-coherent L1$ design. Visibility is commonly provided by barriers. If the user needs memory visibility between the groups in a single dispatch, they decorate the buffer binding with the [globallycoherent] attribute. The shader compiler emits coherent load/store instructions for accesses of that buffer. Since we use 64-bit pointers instead of buffer objects, we offer explicit coherent load/store instructions. The syntax is similar to atomic load/store. Similarly we can provide non-temporal load/store instructions that bypass the whole cache hierarchy.
Vulkan supports 64-bit pointers using the (2019) VK_KHR_buffer_device_address extension (https://docs.vulkan.org/samples/latest/samples/extensions/buffer_device_address/README.html). Buffer device address extension is widely supported by all GPU vendors (including mobile), but is not a part of core Vulkan 1.4. The main issue with BDA is lack of pointer support in the GLSL and the HLSL shader languages. The user has to use raw 64-bit integers instead. A 64-bit integer can be cast to a struct. Structs are defined with custom BDA syntax. Array indexing requires declaring an extra BDA struct type with an array in it, if the user wants the compiler to generate the index addressing math. Debugging support is currently limited. Usability matters a lot and BDA will remain a niche until HLSL and GLSL support pointers natively. This is a stark contrast to CUDA, OpenCL and Metal, where native pointer support is a language core pillar and debugging works flawlessly.
DirectX 12 has no support for pointers in shaders. As a consequence, HLSL doesn’t allow passing arrays as function parameters. Simple things like having a material array inside UBO/SSBO requires hacking around with macros. It’s impossible to make reusable functions for reductions (prefix sum, sort, etc), since groupshared memory arrays can’t be passed between functions. You could of course declare a separate global array for each utility header/library, but the compiler will allocate groupshared memory for each of them separately, reducing occupancy. There’s no easy way to alias groupshared memory. GLSL has identical issues. Pointer based languages like CUDA and Metal MSL don’t have such issues with arrays. CUDA has a vast ecosystem of 3rd party libraries, and this ecosystem makes Nvidia the most valued company on the planet. Graphics shading languages need to evolve to meet modern standards. We need a library ecosystem too.
I will be using a C/C++ style shading language similar to CUDA and Metal MSL in my examples, with some HLSL-style system value (SV) semantics mixed in for the graphics specific bits and pieces.
Root arguments
Operating system threading APIs commonly provide a single 64-bit void pointer to the thread function. The operating system doesn’t care about the user’s data input layout. Let’s apply the same ideology to the GPU kernel data inputs. The shader kernel receives a single 64-bit pointer, which we cast to our desired struct (by the kernel function signature). Developers can use the same shared C/C++ header in both CPU and GPU side.
// Common header...
struct alignas(16) Data
{
// Uniform data
float16x4 color; // 16-bit float vector
uint16x2 offset; // 16-bit integer vector
const uint8* lut; // pointer to 8-bit data array
// Pointers to in/out data arrays
const uint32* input;
uint32* output;
};
// CPU code...
gpuSetPipeline(commandBuffer, computePipeline);
auto data = myBumpAllocator.allocate<Data>(); // Custom bump allocator (wraps gpuMalloc ptr, see appendix)
data.cpu->color = {1.0f, 0.0f, 0.0f, 1.0f};
data.cpu->offset = {16, 0};
data.cpu->lut = luts.gpu + 64; // GPU pointers support pointer math (no need for offset API)
data.cpu->input = input.gpu;
data.cpu->output = output.gpu;
gpuDispatch(commandBuffer, data.gpu, uvec3(128, 1, 1));
// GPU kernel...
[groupsize = (64, 1, 1)]
void main(uint32x3 threadId : SV_ThreadID, const Data* data)
{
uint32 value = data->input[threadId.x];
// TODO: Code using color, offset, lut, etc...
data->output[threadId.x] = value;
}In the example code we use a simple linear bump allocator (myBumpAllocator) for allocating GPU arguments (see appendix for implementation). It returns a struct {void* cpu, void *gpu}. The CPU pointer is used for writing directly to persistently mapped GPU memory and the GPU pointer can be stored to GPU data structures or passed as dispatch command argument.
Most GPUs preload root uniforms (including 64-bit pointers) into constant or scalar registers just before launching a wave. This optimization remains viable: the draw/dispatch command carries the base data pointer. All the input uniforms (including pointers to other data) are found at small fixed offsets from the base pointer. Since shaders are pre-compiled and further optimized into device-specific microcode during the PSO creation, drivers have ample opportunity to set up register preloading and similar root data optimizations. Users should put the most important data in the beginning of the root struct as root data size is limited in some architectures. Our root struct has no hard size limit. The shader compiler will emit standard (scalar/uniform) memory loads for the remaining fields. The root data pointer provided to the shader is const. Shader can’t modify the root input data, as it might be still used by the command processor for preloading data to new waves. Output is done through non-const pointers (see Data::output in above example). By forcing the root data to be const, we also allow GPU drivers to perform their special uniform data path optimizations.
Do we need a special uniform buffer type? Modern shader compilers perform automatic uniformity analysis. If all inputs to an instruction are uniform, the output is also uniform. Uniformity propagates over the shader. All modern architectures have scalar registers/loads or a similar construct (SIMD1 on Intel). Uniformity analysis is used to convert vector loads into scalar loads, which saves registers and reduces latency. Uniformity analysis doesn’t care about the buffer type (UBO vs SSBO). The resource must be readonly (this is why you should always decorate SSBO with readonly attribute in GLSL or prefer SRV over UAV in DirectX 12). The compiler also needs to be able to prove that the pointer is not aliased. The C/C++ const keyword means that data can’t be modified though this pointer, it doesn’t guarantee that other read-write pointers might alias the same memory region. C99 added the restrict keyword for this purpose and CUDA kernels use it frequently. Root pointers in Metal are no-alias (restrict) by default, and so are buffer objects in Vulkan and DirectX 12. We should adopt the same convention to give the compiler more freedom to do optimizations.
The shader compiler is not always able to prove address uniformity at compile time. Modern GPUs opportunistically optimize dynamic uniform address loads. If the memory controller detects that all lanes of a vector load instruction have a uniform address, it emits a single lane load instead of a SIMD wide gather. The result is replicated to all lanes. This optimization is transparent, and doesn’t affect shader code generation or register allocation. Dynamically uniform data is a much smaller performance hit than it used to be in the past, especially when combined with the new fast raw load paths.
Some GPU vendors (ARM Mali and Qualcomm Adreno) take the uniformity analysis a step further. The shader compiler extracts uniform loads and uniform math. A scalar preamble runs before the shader. Uniform memory loads and math is executed once for the whole draw/dispatch and the results are stored in special hardware constant registers (the same registers used by root constants).
All of the above optimizations together provide a better way of handling uniform data than the classic 16KB/64KB uniform/constant buffer abstraction. Many GPUs still have special uniform registers for root constants, system values and the preamble (see above paragraph).
Texture bindings
Ideally, texture descriptors would behave like any other data in GPU memory, allowing them to be freely mixed in structs with other data. However, this level of flexibility isn't universally supported by all modern GPUs. Fortunately bindless texture sampler designs have converged over the last decade, with only two primary methods remaining: 256-bit raw descriptors and the indexed descriptor heap.
AMDs raw descriptor method loads 256-bit descriptors directly from GPU memory into the compute unit’s scalar registers. Eight subsequent 32-bit scalar registers contain a single descriptor. During the SIMD texture sample instruction, the shader core sends a 256-bit texture descriptor and per-lane UVs to the sampler unit. This provides the sampler all the data it needs to address and load texels without any indirections. The drawback is that the 256-bit descriptor takes a lot of register space and needs to be resent to the sampler for each sample instruction.
The indexed descriptor heap approach uses 32-bit indices (20 bits for old Intel iGPUs). 32-bit indices are trivial to store in structs, load into standard SIMD registers and efficient to pass around. During a SIMD sample instruction, the shader core sends the texture index and the per-lane UVs to the sampler unit. The sampler fetches the descriptor from the descriptor heap: heap base address + texture index * stride (256-bits in modern GPUs). The texture heap base address is either abstracted by the driver (Vulkan and Metal) or provided by the user (SetDescriptorHeaps in DirectX 12). Changing the texture heap base address may result in an internal pipeline barrier (on older hardware). On modern GPUs the texture heap 64-bit base address is often part of each sample instruction data, allowing sampling from multiple heaps seamlessly (64-bit base + 32-bit offset per lane). The sampler unit has a tiny internal descriptor cache to avoid indirect reads after the first access. Descriptor caches must be invalidated whenever the descriptor heap is modified.
A few years ago it looked like AMDs scalar register based texture descriptors were the winning formula in the long run. Scalar registers are more flexible than a descriptor heap, allowing descriptors to be embedded inside GPU data structures directly. But there’s a downside. Modern GPU workloads such as ray-tracing and deferred texturing (Nanite) lean on non-uniform texture indices. The texture heap index is not uniform over a SIMD wave. A 32-bit heap index is just 4 bytes, we can send it per lane. In contrast, a 256-bit descriptor is 32 bytes. It is not feasible to fetch and send a full 256-bit descriptor per lane. Modern Nvidia, Apple and Qualcomm GPUs support per-lane descriptor index mode in their sample instructions, making the non-uniform case more efficient. The sampler unit performs an internal loop if required. Inputs/outputs to/from sampler units are sent once, regardless of the heap index coherence. AMDs scalar register based descriptor architecture requires the shader compiler to generate a scalarization loop around the texture sample instruction. This costs extra ALU cycles and requires sending and receiving (partially masked) sampler data multiple times. It’s one of the reasons why Nvidia is faster in ray-tracing than AMD. ARM and Intel use 32-bit heap indices too (like Nvidia, Qualcomm and Apple), but their latest architectures don’t yet have a per-lane heap index mode. They emit a similar scalarization loop as AMD for the non-uniform index case.
All of these differences can be wrapped under an unified texture descriptor heap abstraction. The de-facto texture descriptor size is 256 bits (192 bits on Apple for a separate texture descriptor, sampler is the remaining 32 bits). The texture heap can be presented as a homogeneous array of 256-bit descriptor blobs. Indexing is trivial. DirectX 12 shader model 6.6 provides a texture heap abstraction like this, but doesn’t allow direct CPU or compute shader write access to the descriptor heap memory. A set of APIs are used for creating descriptors and copying descriptors from the CPU to the GPU. The GPU is not allowed to write the descriptors. Today, we can remove this API abstraction completely by allowing direct CPU and GPU write to the descriptor heap. All we need is a simple (user-land) driver helper function for creating a 256-bit (uint64[4]) hardware specific descriptor blob. Modern GPUs have UMA or PCIe ReBAR. The CPU can directly write descriptor blobs into GPU memory. Users can also use compute shaders to copy or generate descriptors. The shader language has a descriptor creation intrinsic too. It returns a hardware specific uint64x4 descriptor blob (analogous to the CPU API). This approach cuts the API complexity drastically and is both faster and more flexible than the DirectX 12 descriptor update model. Vulkan’s VK_EXT_descriptor_buffer (https://www.khronos.org/blog/vk-ext-descriptor-buffer) extension (2022) is similar to my proposal, allowing direct CPU and GPU write. It is supported by most vendors, but unfortunately is not part of the Vulkan 1.4 core spec.
// App startup: Allocate a texture descriptor heap (for example 65536 descriptors)
GpuTextureDescriptor *textureHeap = gpuMalloc<GpuTextureDescriptor>(65536);
// Load an image using a 3rd party library
auto pngImage = pngLoad("cat.png");
auto uploadMemory = uploadBumpAllocator.allocate(pngImage.byteSize); // Custom bump allocator (wraps gpuMalloc ptr)
pngImage.load(uploadMemory.cpu);
// Allocate GPU memory for our texture (optimal layout with metadata)
GpuTextureDesc textureDesc { .dimensions = pngImage.dimensions, .format = FORMAT_RGBA8_UNORM, .usage = SAMPLED };
GpuTextureSizeAlign textureSizeAlign = gpuTextureSizeAlign(textureDesc);
void *texturePtr = gpuMalloc(textureSizeAlign.size, textureSizeAlign.align, MEMORY_GPU);
GpuTexture texture = gpuCreateTexture(textureDesc, texturePtr);
// Create a 256-bit texture view descriptor and store it
textureHeap[0] = gpuTextureViewDescriptor(texture, { .format = FORMAT_RGBA8_UNORM });
// Batched upload: begin
GpuCommandBuffer uploadCommandBuffer = gpuStartCommandRecording(queue);
// Copy all textures here!
gpuCopyToTexture(uploadCommandBuffer, texturePtr, uploadMemory.gpu, texture);
// TODO other textures...
// Batched upload: end
gpuBarrier(uploadCommandBuffer, STAGE_TRANSFER, STAGE_ALL, HAZARD_DESCRIPTORS);
gpuSubmit(queue, { uploadCommandBuffer });
// Later during rendering...
gpuSetActiveTextureHeapPtr(commandBuffer, gpuHostToDevicePointer(textureHeap));It is almost possible to get rid of the CPU side texture object (GpuTexture) completely. Unfortunately the triangle rasterizer units of all modern GPUs are not yet bindless. The CPU driver needs to prepare command packets to bind render targets, depth-stencil buffers, clear and resolve. These APIs don’t use the 256-bit GPU texture descriptor. We need driver specific extra CPU data (stored in the GpuTexture object).
The simplest way to reference a texture in a shader is to use a 32-bit index. A single index can also represent the starting offset of a range of descriptors. This offers a straightforward way to implement the DirectX 12 descriptor table abstraction and the Vulkan descriptor set abstraction without an API. We also get an elegant solution to the fast material switch use case: All we need is a single 64-bit GPU pointer, pointing to a material data struct (containing material properties + 32-bit texture heap start index). Vulkan vkCmdBindDescriptorSets and DirectX 12 SetGraphicsRootDescriptorTable are relatively fast API calls, but they are nowhere as fast as writing a single 64-bit pointer to persistently mapped GPU memory. A lot of complexity is removed by not needing to create, update and delete resource binding API objects. CPU time is also saved as the user no longer needs to maintain a hash map of descriptor sets, a common approach to solve the immediate vs retained mode discrepancy in game engines.
// Common header...
struct alignas(16) Data
{
uint32 srcTextureBase;
uint32 dstTexture;
float32x2 invDimensions;
};
// GPU kernel...
const Texture textureHeap[];
[groupsize = (8, 8, 1)]
void main(uint32x3 threadId : SV_ThreadID, const Data* data)
{
Texture textureColor = textureHeap[data->srcTextureBase + 0];
Texture textureNormal = textureHeap[data->srcTextureBase + 1];
Texture texturePBR = textureHeap[data->srcTextureBase + 2];
Sampler sampler = {.minFilter = LINEAR, .magFilter = LINEAR}; // Embedded sampler (Metal-style)
float32x2 uv = float32x2(threadId.xy) * data->invDimensions;
float32x4 color = sample(textureColor, sampler, uv);
float32x4 normal = sample(textureNormal, sampler, uv);
float32x4 pbr = sample(texturePBR, sampler, uv);
float32x4 lit = calculateLighting(color, normal, pbr);
TextureRW dstTexture = TextureRW(textureHeap[data->dstTexture]);
dstTexture[threadId.xy] = lit;
}Metal 4 manages the texture descriptor heap automatically. Texture objects have .gpuResourceID, which is a 64-bit heap index (Xcode GPU debugger reveals small values such as 0x3). You can directly write texture IDs into GPU structs, as you would use texture indices in DirectX SM 6.6 and Vulkan (descriptor buffer extension). As the heap management in Metal is automatic, users can’t allocate texture descriptors in contiguous ranges. It’s a common practice to store a 32-bit index to the first texture in the range and calculate the indices for other textures in the set (see above code example). Metal doesn’t support this. The user has to write a 64-bit texture handle for each texture separately. To address a set of 5 textures, you need 40 bytes in Metal (5 * 64-bit). Vulkan and DirectX 12 only need 4 bytes (1 * 32-bit). Apple GPU hardware is able to implement SM 6.6 texture heaps. The limitation is the Metal API (software).
Texel buffers can be still supported for backwards compatibility. DirectX 12 stores texel buffer descriptors in the same heap with texture descriptors. A texel buffer functions similarly to a 1d texture (unfiltered tfetch path). Since texel buffers would be mainly used for backwards compatibility, driver vendors wouldn’t need to jump over the hoops to replace them with faster code paths such as raw memory loads behind the scenes. I am not a big fan of driver background threads and shader replacements.
Non-uniform texture index needs to use NonUniformResourceIndex notation similar to GLSL and HLSL. This tells the low level GPU shader compiler to emit a special texture instruction with per-lane heap index, or a scalarization loop for GPUs that only support uniform descriptors. Since buffers are not descriptors, we never need NonUniformResourceIndex for buffers. We simply pass a 64-bit pointer per lane. It works on all modern GPUs. No scalarization loop, no mess. Additionally, the language should natively support ptr[index] notation for memory loads, where the index is 32-bits. Some GPUs support raw memory load instructions with 32-bit per lane offset. It reduces the register pressure. Feedback to GPU vendors: Please add the missing 64-bit shared base + 32-bit per lane offset raw load instruction and 16-bit uv(w) texture load instructions, if your architecture is still missing them.
const Texture textureHeap[];
[groupsize = (8, 8, 1)]
void main(uint32x3 threadId : SV_ThreadID, const Data* data)
{
// Non-uniform "buffer data" is not an issue with pointer semantics!
Material* material = data->materialMap[threadId.xy];
// Non-uniform texture heap index
uint32 textureBase = NonUniformResourceIndex(material.textureBase);
Texture textureColor = textureHeap[textureBase + 0];
Texture textureNormal = textureHeap[textureBase + 1];
Texture texturePBR = textureHeap[textureBase + 2];
Sampler sampler = {.minFilter = LINEAR, .magFilter = LINEAR};
float32x2 uv = float32x2(threadId.xy) * data->invDimensions;
float32x4 color = sample(textureColor, sampler, uv);
float32x4 normal = sample(textureNormal, sampler, uv);
float32x4 pbr = sample(texturePBR, sampler, uv);
color *= material.color;
pbr *= material.pbr;
// Rest of the shader
}Modern bindless texturing lets us remove all texture binding APIs. A global indexable texture heap makes all textures visible to all shaders. Texture data still needs to be loaded into GPU memory by copy commands (to enable DCC and Morton swizzle). Texture descriptor creation still needs a thin GPU specific user land API. The texture heap can be exposed directly to both the CPU and the GPU as a raw GPU memory array, removing most of the texture heap API complexity compared to DirectX 12 SM 6.6.
Shader pipelines
Since our shader root data is just a single 64-bit pointer and our textures are just 32-bit indices, the shader pipeline creation becomes dead simple. There’s no need to define texture bindings, buffer bindings, bind groups (descriptor sets, argument buffers) or the root signature.
auto shaderIR = loadFile("computeShader.ir");
GpuPipeline computePipeline = gpuCreateComputePipeline(shaderIR);DirectX 12 and Vulkan utilize complex APIs to bind and set up root signatures, push descriptors, push constants, and descriptor sets. A modern GPU driver essentially constructs a single struct into GPU memory and passes its pointer to the command processor. We have shown that such API complexity is unnecessary. The user simply writes the root struct into persistently mapped GPU memory and passes a 64-bit GPU pointer directly to the draw/dispatch function. Users can also include 64-bit pointers and 32-bit texture heap indices inside their structs to build any indirect data layout that fits their needs. Root bindings APIs and the whole DX12 buffer zoo can be replaced efficiently with 64-bit pointers. This simplifies the shader pipeline creation drastically. We don’t need to define the data layout at all. We successfully removed a massive chunk of API complexity while providing more flexibility to the user.
Static constants
Vulkan, Metal and WebGPU have a concept of static (specialization) constants, locked in at shader pipeline creation. The driver's internal shader compiler applies these constants as literals in the input shader IR and does constant propagation and dead code elimination pass afterward. This can be used to create multiple permutations of the same shader at pipeline creation, reducing the time and storage required for offline compiling all the shader permutations.
Vulkan and Metal have a set of APIs and a special shader syntax for describing the shader specialization constants and their values. It would be nicer to simply provide a C struct that matches the constant struct defined in the shader side. That would require minimal API surface and would bring important improvements.
Vulkan’s specialization constants have a design flaw. Specialization constants can’t modify the descriptor set layouts. Data inputs and outputs are fixed. The user could hack around the limitation by implementing an uber-layout containing all potential inputs/outputs and skip updating unused descriptors, but this is cumbersome and sub-optimal. Our proposed design doesn’t have the same problem. One can simply branch by a constant (the other side is dead code eliminated) and reinterpret the shader data input pointer as a different struct. One could also mimic the C++ inheritance data layout. Use a common layout for the beginning of the input struct and put specialized data at the end. Static polymorphism can be achieved cleanly. Runtime performance is identical to hand optimized shader. The specialization struct can also include GPU pointers, allowing the user to hardcode runtime memory locations, avoiding indirections. This has never been possible in a shader language before. Instead, the GPU vendors had to use background threads to analyze the shaders to do similar shader replacement optimizations at runtime, increasing the CPU cost and the driver complexity significantly.
// Common header...
struct alignas(16) Constants
{
int32 qualityLevel;
uint8* blueNoiseLUT;
};
// CPU code...
Constants constants { .qualityLevel = 2, blueNoiseLUT = blueNoiseLUT.gpu };
auto shaderIR = loadFile("computeShader.ir");
GpuPipeline computePipeline = gpuCreateComputePipeline(shaderIR, &constants);
// GPU kernel...
[groupsize = (8, 8, 1)]
void main(uint32x3 threadId : SV_ThreadID, const Data* data, const Constants constants)
{
if (constants.qualityLevel == 3)
{
// Dead code eliminated
}
}The shader permutation hell is one of the biggest issues in modern graphics today. Gamers are complaining about stutter, devs are complaining about offline shader compilation taking hours. This new design gives the user added flexibility. They can toggle between static and dynamic behavior inside the shader, making it easy to have a generic fallback and specialization on demand. This design reduces the number of shader permutations and the runtime stalls caused by pipeline creation.
Barriers and fences
The most hated feature in modern graphics APIs must be the barriers. Barriers serve two purposes: enforce producer-to-consumer execution dependencies and transition textures between layouts.
Many graphics programmers have an incorrect mental model about the GPU synchronization. A common belief is that GPU synchronization is based on fine-grained texture and buffer dependencies. In reality, modern GPU hardware doesn’t really care about individual resources. We spend lots of CPU cycles in userland preparing a list of individual resources and how their layouts change, but modern GPU drivers practically throw that list away. The abstraction doesn’t match reality.
Modern bindless architecture gives the GPU a lot of freedom. A shader can write to any 64-bit pointer or any texture in the global descriptor heap. The CPU doesn't know what decisions the GPU is going to make. How is it supposed to emit transition barriers for each affected resource? This is a clear mismatch between bindless architecture and classic CPU-driven rendering APIs today. Let’s investigate why the APIs were designed like this 10 years ago.
AMD GCN had a big influence on modern graphics API design. GCN was ahead of its time with async compute and bindless texturing (using scalar registers to store descriptors), but it also had crucial limitations in its delta color compression (DCC) and cache design. These limitations are a great example why the barrier model we have today is so complex. GCN didn’t have a coherent last-level cache. ROPs (raster operations = pixel shader outputs) had special non-coherent caches directly connected to the VRAM. The driver had to first flush the ROP caches to memory and then invalidate the L2$ to make pixel shader writes visible to shaders and samplers. The command processor also wasn’t a client of the L2$. Indirect arguments written in compute shaders weren’t visible to the command processor without invalidating the whole L2$ and flushing all dirty lines into VRAM. GCN 3 introduced delta color compression (DCC) for ROPs, but AMD’s texture samplers were not able to directly read DCC compressed textures or compressed depth buffers. The driver had to perform an internal decompress compute shader to eliminate the compression. The display engine could not read DCC compressed textures either. The common case of sampling a render target required two internal barriers and flushing all caches (wait for ROPs, flush ROP cache and L2$, run decompress compute shader, wait for compute).
AMD’s new RDNA architecture has several crucial improvements: It has a coherent L2$ covering all memory operations. ROPs and the command processor are clients of the L2$. The only non-coherent caches are the tiny L0$ and K$ (scalar cache) inside the compute units. A barrier now requires only flushing the outstanding writes in the tiny caches into the higher level cache. The driver no longer has to flush the last-level (L2) cache into the VRAM, making barriers significantly faster. RDNA’s improved display engine is capable of reading DCC compressed textures and a (de)compressor sits between the L2$ and the L0$ texture cache. There’s no need to decompress textures into VRAM before sampling, removing the need for texture layout transitions (compressed / uncompressed). All desktop and mobile GPU vendors have reached similar conclusions: Bandwidth is the bottleneck today. We should never waste bandwidth decoding resources into VRAM. Layout transitions are no longer needed.

AMD RDNA (2019): Improved cache hierarchy, DCC and display engine in the RDNA architecture. L2$ contains DCC compressed data. (De)compressor sits between L2$ and lower levels. L0$ (texture) is decompressed. Image © AMD.
Resource lists are the most annoying aspect of barriers in DirectX 12 and Vulkan. Users are expected to track the state of each resource individually, and tell the graphics API their previous and next state for each barrier. This was necessary on 10 year old GPUs as vendors hid various decompress commands under the barrier API. The barrier command functioned as the decompress command, so it had to know which resources required decompression. Today’s hardware doesn’t need texture layouts or decompress steps. Vulkan just got a new VK_KHR_unified_image_layouts (https://www.khronos.org/blog/so-long-image-layouts-simplifying-vulkan-synchronisation) extension (2025), removing the image layout transitions from the barrier command. But it still requires the user to list individual textures and buffers. Why is this?
The main reason is legacy API and tooling compatibility. People are used to thinking about resource dependencies and the existing Vulkan and DirectX 12 validation layers are designed that way. However, the barrier command executed by the GPU contains no information about textures or buffers at all. The resource list is consumed solely by the driver.
Our modern driver loops through your resource list and populates a set of flags. Drivers no longer need to worry about resource layouts or last level cache coherency, but there still exists tiny non-coherent caches that need flushing in special cases. Modern GPUs flush the majority of the non-coherent caches automatically in every barrier. For example the AMD L0$ and K$ (scalar cache) are always flushed, since every pass writes some outputs and these outputs live in some of these caches. Fine grained tracking of all write addresses would be too expensive. Tiny non-coherent caches tend to be inclusive. Modified lines get flushed to the next cache level. This is fast and doesn’t produce VRAM traffic. Some architectures have special caches that are not automatically flushed. Examples: descriptor caches in the texture samplers (see above chapter), rasterizer ROP caches and HiZ caches. The command processor commonly runs ahead to reduce the wave spawn latency. If we write indirect arguments in a shader, we need to inform the GPU to stall the command processor prefetcher to avoid a race. The GPU doesn’t actually know whether your compute shader was writing into an indirect argument buffer or not. In DirectX 12 the buffer is transitioned to D3D12_RESOURCE_STATE_INDIRECT_ARGUMENT and in Vulkan the consumer dependency has a special stage VK_PIPELINE_STAGE_DRAW_INDIRECT_BIT. When a barrier has a resource transition like this or a stage dependency like this, the driver will include command processor prefetcher stall flag into the barrier.
A modern barrier design replaces the resource list with a single bitfield describing what happens to these special non-coherent caches. Special cases include: Invalidate texture descriptors, invalidate draw arguments and invalidate depth caches. These flags are needed when we generate draw arguments, write to the descriptor heap or write to a depth buffer with a compute shader. Most barriers don’t need special cache invalidation flags.
Some GPUs still need to decompress data in special cases. For example during a copy or a clear command (fast clear eliminate if clear color has changed). Copy and clear commands take the affected resource as a parameter. The driver can take necessary steps to decode the data if needed. We don’t need a resource list in our barrier for these special cases. Not all formats and usage flags support compression. The driver will keep the data uncompressed in these cases, instead of transitioning it back and forth, wasting bandwidth.
A standard UAV barrier (compute → compute) is trivial.
gpuBarrier(commandBuffer, STAGE_COMPUTE, STAGE_COMPUTE);If you write to the texture descriptor heap (uncommon), you need to add a special flag.
gpuBarrier(commandBuffer, STAGE_COMPUTE, STAGE_COMPUTE, HAZARD_DESCRIPTORS);A barrier between rasterizer output and pixel shader is a common case for offscreen render target → sampling. Our example has dependency stages set up in a way that the barrier doesn’t block vertex shaders, allowing vertex shading (and tile binning on mobile GPUs) to overlap with previous passes. A barrier with raster output stage (or later) as the producer automatically flushes non-coherent ROP caches if the GPU architecture needs that. We don’t need an explicit flag for it.
gpuBarrier(commandBuffer, STAGE_RASTER_COLOR_OUT | STAGE_RASTER_DEPTH_OUT, STAGE_PIXEL_SHADER);Users only describe the queue execution dependencies: producer and consumer stage masks. There’s no need to track the individual texture and buffer resource states, removing a lot of complexity and saving a significant amount of CPU time versus the current DirectX 12 and Vulkan designs. Metal 2 has a modern barrier design already: it doesn’t use resource lists.
Many GPUs have custom scratchpads memories: Groupshared memory inside each compute unit, tile memory, large shared scratchpads like the Qualcomm GMEM. These memories are managed automatically by the driver. Temporary scratchpads like groupshared memory are never stored to memory. Tile memories are stored automatically by the tile rasterizer (store op == store). Uniform registers are read-only and pre-populated before each draw call. Scratchpads and uniform registers don’t have cache coherency protocols and don’t interact with the barriers directly.
Modern GPUs support a synchronization command that writes a value to memory when a shader stage is finished, and a command that waits for a value to appear in memory location before a shader stage is allowed to begin (wait includes optional cache flush semantics). This is equivalent to splitting the barrier into two: the producer and the consumer. DirectX 12 split barriers and Vulkan event→wait are examples of this design. Splitting the barrier into consumer→producer allows putting independent work between them, avoiding draining the GPU.
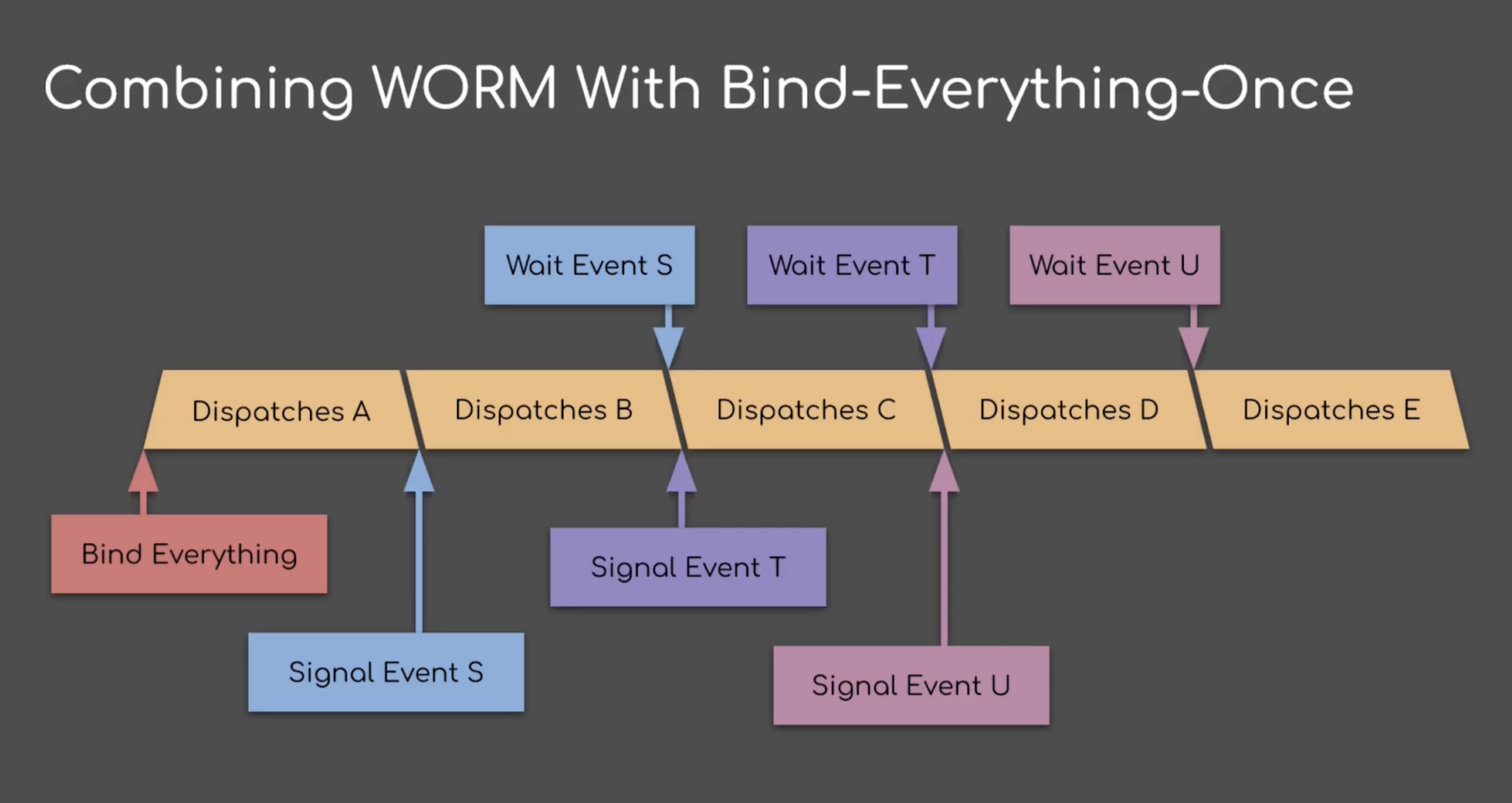
Vulkan event→wait (and DX12 split barriers) see barely any use. The main reason is that normal barriers are already highly complicated, and developers want to avoid extra complexity. Driver support for split barriers also hasn’t been perfect in the past. Removing the resource lists simplifies the split barriers significantly. We can also make split barriers semantically similar to timeline semaphores: Signal command writes to a monotonically increasing 64-bit value (atomic max) and wait command waits for the value to be >= N (greater equal). The counter is just a GPU memory pointer, no persistent API object is required. This provides us with a significantly simpler event→wait API.
gpuSignalAfter(commandBuffer, STAGE_RASTER_COLOR_OUT, gpuPtr, counter, SIGNAL_ATOMIC_MAX);
// Put independent work here
gpuWaitBefore(commandBuffer, STAGE_PIXEL_SHADER, gpuPtr, counter++, OP_GREATER_EQUAL);This API is much simpler than the existing VkEvent API, yet offers improved flexibility. In the above example we implemented the timeline semaphore semantics, but we can implement other patterns too, such as waiting multiple producers using a bitmask: mark bits with SIGNAL_ATOMIC_OR and wait for all bits in a mask to be set (mask is an optional parameter in the gpuWaitBefore command).
Cascading signal→wait with independent work between producer→consumer avoids GPU stalls. Image © Timothy Lottes.
GPU→CPU synchronization was initially messy in Vulkan and Metal. Users needed a separate fence object for each submit. N buffering was a common technique for reusing the objects. This is a similar usability issue as discussed above regarding VkEvent. DirectX 12 was the first API to solve the GPU→CPU synchronization cleanly with timeline semaphores. Vulkan 1.2 and Metal 2 adapted the same design later. A timeline semaphore needs only a single 64-bit monotonically increasing counter. This reduces complexity over the older Vulkan and Metal fence APIs, which many engines still use today.
#define FRAMES_IN_FLIGHT 2
GpuSemaphore frameSemaphore = gpuCreateSemaphore(0);
uint64 nextFrame = 1;
while (running)
{
if (nextFrame > FRAMES_IN_FLIGHT)
{
gpuWaitSemaphore(frameSemaphore, nextFrame - FRAMES_IN_FLIGHT);
}
// Render the frame here
gpuSubmit(queue, {commandBuffer}, frameSemaphore, nextFrame++);
}
gpuDestroySemaphore(frameSemaphore);Our proposed barrier design is a massive improvement over DirectX 12 and Vulkan. It reduces the API complexity significantly. Users no longer need to track individual resources. Our simple hazard tracking has queue + stage granularity. This matches what GPU hardware does today. Game engine graphics backends can be simplified and CPU cycles are saved.
Command buffers
Vulkan and DirectX 12 were designed to promote the pre-creation and reuse of resources. Early Vulkan examples recorded a single command buffer at startup, replaying it every frame. Developers quickly discovered that command buffer reuse was impractical. Real game environments are dynamic and the camera is in constant motion. The visible object set changes frequently.
Game engines ignored prerecorded command buffers entirely. Metal and WebGPU feature transient command buffers, which are created just before recording and disappear after GPU has finished rendering. This eliminates the need for command buffer management and prevents multiple submissions of the same commands. GPU vendors recommend one shot command buffers (a resettable command pool per frame in flight) in Vulkan too, as it simplifies the driver’s internal memory management (bump allocator vs heap allocator). The best practices match Metal and WebGPU design. Persistent command buffer objects can be removed. That API complexity didn’t provide anything worth using.
while (running)
`
GpuCommandBuffer commandBuffer = gpuStartCommandRecording(queue);
// Render frame here
}Graphics shaders
Let’s start with a burning question: Do we need graphics shaders anymore? UE5 Nanite uses compute shaders to plot pixels using 64-bit atomics. High bits contain the pixel depth and low bits contain the payload. Atomic-min ensures that the closest surface remains. This technique was first presented at SIGGRAPH 2015 by Media Molecule Dreams (Alex Evans). Hardware rasterizer still has some advantages, like hierarchical/early depth-stencil tests. Nanite has to lean solely on coarse cluster culling, which results in extra overdraw with kitbashed content. Ubisoft (me and Ulrich Haar) presented this two-pass cluster culling algorithm at SIGGRAPH 2015. Ubisoft used cluster culling in combination with the hardware rasterizer for more fine grained culling. Today’s GPUs are bindless and much better suited for GPU-driven workloads like this. 10 years ago Ubisoft had to lean on virtual texturing (all textures in the same atlas) instead of bindless texturing. Despite many compute-only rasterizers today (Nanite, SDF sphere tracing, DDA voxel tracing) the hardware rasterizer still remains the most used technique for rendering triangles in games today. It’s definitely worth discussing how to make the rasterization pipeline more flexible and easier to use.
The modern shader framework has grown to 16 shader entry points. We have eight entry points for rasterization (pixel, vertex, geometry, hull, domain, patch constant, mesh and amplification), and six for ray-tracing (ray generation, miss, closest hit, any hit, intersection and callable). In comparison, CUDA has a single entry point: kernel. This makes CUDA composable. CUDA has a healthy ecosystem of 3rd party libraries. New GPU hardware blocks such as the tensor cores (AI) are exposed as intrinsic functions. This is how it all started in the graphics land as well: texture sampling was our first intrinsic function. Today, texture sampling is fully bindless and doesn’t even require driver setup. This is the design developers prefer. Simple, easy to compose, and extend.
We recently got more intrinsics: inline raytracing and cooperative matrix (wave matrix in DirectX 12, subgroup matrix in Metal). I am hoping that this is the new direction. We should start tearing down the massive 16 shader framework and replacing it with intrinsics that can be composed in a flexible way.
Solving the shader framework complexity is a massive topic. To keep the scope of this blog post in check, I will today only discuss compute shaders and raster pipelines. I am going to be writing a followup about simplifying the shader framework, including modern topics such as ray-tracing, shader execution reordering (SER), dynamic register allocation extensions and Apple’s new L1$ backed register file (called dynamic caching).
Raster pipelines
There are two relevant raster pipelines today: Vertex+pixel and mesh+pixel. Mobile GPUs employing tile based deferred rendering (TBDR) perform per-triangle binning. Tile size is commonly between 16x16 to 64x64 pixels, making meshlets too coarse grained primitive for binning. Meshlet has no clear 1:1 lane to vertex mapping, there’s no straightforward way to run a partial mesh shader wave for selected triangles. This is the main reason mobile GPU vendors haven’t been keen to adapt the desktop centric mesh shader API designed by Nvidia and AMD. Vertex shaders are still important for mobile.
I will not be discussing geometry, hull, domain, and patch constant (tessellation) shaders. The graphics community widely considers these shader types as failed experiments. They all have crucial performance issues in their design. In all relevant use cases, you can run a compute prepass generating an index buffer to outperform these stages. Additionally, mesh shaders allow generating a compact 8-bit index buffer into on-chip memory, further increasing the performance gap over these legacy shader stages.
Our goal is to build a modern PSO abstraction with a minimal amount of baked state. One of the main critiques of Vulkan and DirectX 12 has been the pipeline permutation explosion. The less state we have inside the PSO, the less pipeline permutations we get. There are two main areas to improve: graphics shader data bindings and the rasterizer state.
Graphics shader bindings
Vertex+pixel shader pipeline needs several additional inputs compared to a compute kernel: vertex buffers, index buffer, rasterizer state, render target views and a depth-stencil view. Let’s start by discussing the shader visible data bindings.
Vertex buffer bindings are easy to solve: We simply remove them. Modern GPUs have fast raw load paths. Most GPU vendors have been emulating vertex fetch hardware already for several generations. Their low level shader compiler reads the user defined vertex layout and emits appropriate raw load instructions in the beginning of the vertex shader.
The vertex bindings declaration is another example of a special C/C++ API for defining a struct memory layout. It adds complexity and forces compiling multiple PSO permutations for different layouts. We simply replace the vertex buffers with standard C/C++ structs. No API is required.
// Common header...
struct Vertex
{
float32x4 position;
uint8x4 normal;
uint8x4 tangent;
uint16x2 uv;
};
struct alignas(16) Data
{
float32x4x4 matrixMVP;
const Vertex *vertices;
};
// CPU code...
gpuSetPipeline(commandBuffer, graphicsPipeline);
auto data = myBumpAllocator.allocate<Data>();
data.cpu->matrixMVP = camera.viewProjection * modelMatrix;
data.cpu->vertices = mesh.vertices;
gpuDrawIndexed(commandBuffer, data.gpu, mesh.indices, mesh.indexCount);
// Vertex shader...
struct VertexOut
{
float32x4 position : SV_Position;
float16x4 normal;
float32x2 uv;
};
VertexOut main(uint32 vertexIndex : SV_VertexID, const Data* data)
{
Vertex vertex = data->vertices[vertexIndex];
float32x4 position = data->matrixMVP * vertex.position;
// TODO: Normal transform here
return { .position = position, .normal = normal, .uv = vertex.uv };
}The same is true for per-instance data and multiple vertex streams. We can implement them efficiently with raw memory loads. When we use raw load instructions, we can dynamically adjust the vertex stride, branch over secondary vertex buffer loads and calculate our vertex indices using custom formulas to implement clustered GPU-driven rendering, particle quad expansion, higher order surfaces, efficient terrain rendering and many other algorithms. Additional shader entry points and binding APIs are not needed. We can use our new static constant system to dead code eliminate vertex streams at pipeline creation or provide a static vertex stride if we so prefer. All the old optimization strategies still exist, but we can now mix and match techniques freely to match our renderer’s needs.
// Common header...
struct VertexPosition
{
float32x4 position;
};
struct VertexAttributes
{
uint8x4 normal;
uint8x4 tangent;
uint16x2 uv;
};
struct alignas(16) Instance
{
float32x4x4 matrixModel;
}
struct alignas(16) Data
{
float32x4x4 matrixViewProjection;
const VertexPosition *vertexPositions;
const VertexAttributes *vertexAttribues;
const Instance *instances;
};
// CPU code...
gpuSetPipeline(commandBuffer, graphicsPipeline);
auto data = myBumpAllocator.allocate<Data>();
data.cpu->matrixViewProjection = camera.viewProjection;
data.cpu->vertexPositions = mesh.positions;
data.cpu->vertexAttributes = mesh.attributes;
data.cpu->instances = batcher.instancePool + instanceOffset; // pointer arithmetic is convenient
gpuDrawIndexedInstanced(commandBuffer, data.gpu, mesh.indices, mesh.indexCount, instanceCount);
// Vertex shader...
struct VertexOut
{
float32x4 position : SV_Position; // SV values are not real struct fields (doesn't affect the layout)
float16x4 normal;
float32x2 uv;
};
VertexOut main(uint32 vertexIndex : SV_VertexID, uint32 instanceIndex : SV_InstanceID, const Data* data)
{
Instance instance = data->instances[SV_InstanceIndex];
// NOTE: Splitting positions/attributes benefits TBDR GPUs (vertex shader is split in two parts)
VertexPosition vertexPosition = data->vertexPositions[SV_VertexIndex];
VertexAttributes vertexAttributes = data->vertexAttributes[SV_VertexIndex];
float32x4x4 matrix = data->matrixViewProjection * instance.matrixModel;
float32x4 position = matrix * vertexPosition.position;
// TODO: Normal transform here
return { .position = position, .normal = normal, .uv = vertexAttributes.uv };
}The index buffer binding is still special. GPUs have index deduplication hardware. We don’t want to run the vertex shader twice for the same vertex. The index deduplication hardware packs the vertex waves eliminating duplicate vertices. Index buffering is still a crucial optimization today. Non-indexed geometry executes 3 vertex shader invocations (lanes) per triangle. A perfect grid has two triangles per cell, thus it only needs one vertex shader invocation per two triangles (ignoring the last row/column). Modern offline vertex cache optimizers output meshes with around 0.7 vertices per triangle efficiency. We can achieve around 4x to 6x reduction in vertex shading cost with index buffer in real world scenarios.
The index buffer hardware nowadays connects to the same cache hierarchy as all the other GPU units. Index buffer is simply an extra GPU pointer in the drawIndexed call. That’s the sole API surface we need for index buffering.
Mesh shaders lean on offline vertex deduplication. A common implementation shades one vertex per lane, and outputs it into on-chip memory. An 8-bit local index buffer tells the rasterizer which 3 vertices are used by each triangle. Since all the meshlet outputs are available at once and are already transformed in on-chip storage, there’s no need to deduplicate or pack vertices after triangle setup. This is why mesh shaders don’t need the index deduplication hardware or the post transform cache. All mesh shader inputs are raw data. No extra API surface is needed beyond the gpuDrawMeshlets command.
My example mesh shader uses 128 lane thread groups. Nvidia supports up to 126 vertices and 64 triangles per output meshlet. AMD supports 256 vertices and 128 triangles. The shader masks out excess lanes. Since there’s never more than 64 triangles, you might also opt for a 64 lane thread group for optimal triangle lane utilization and do a two iteration loop for vertex shading. My triangle fetch logic is just a single memory load instruction, wasting half of the lanes there isn’t a problem. I chose the extra parallelism for vertex shading instead. Optimal choices depend on your workload and the target hardware.
// Common header...
struct Vertex
{
float32x4 position;
uint8x4 normal;
uint8x4 tangent;
uint16x2 uv;
};
struct alignas(16) Meshlet
{
uint32 vertexOffset;
uint32 triangleOffset;
uint32 vertexCount;
uint32 triangleCount;
};
struct alignas(16) Data
{
float32x4x4 matrixMVP;
const Meshlet *meshlets;
const Vertex *vertices;
const uint8x4 *triangles;
};
// CPU code...
gpuSetPipeline(commandBuffer, graphicsMeshPipeline);
auto data = myBumpAllocator.allocate<Data>();
data.cpu->matrixMVP = camera.viewProjection * modelMatrix;
data.cpu->meshlets = mesh.meshlets;
data.cpu->vertices = mesh.vertices;
data.cpu->triangles = mesh.triangles;
gpuDrawMeshlets(commandBuffer, data.gpu, uvec3(mesh.meshletCount, 1, 1));
// Mesh shader...
struct VertexOut
{
float32x4 position : SV_Position;
float16x4 normal;
float32x2 uv;
};
[groupsize = (128, 1, 1)]
void main(uint32x3 groupThreadId : SV_GroupThreadID, uint32x3 groupId : SV_GroupID, const Data* data)
{
Meshlet meshlet = data->meshlets[groupId.x];
// Meshlet output allocation intrinsics
VertexOut* outVertices = allocateMeshVertices<VertexOut>(meshlet.vertexCount);
uint8x3* outIndices = allocateMeshIndices(meshlet.triangleCount);
// Triangle indices (3x 8 bit)
if (groupThreadId.x < meshlet.triangleCount)
{
outIndices[groupThreadId.x] = triangles[meshlet.triangleOffset + groupThreadId.x].xyz;
}
// Vertices
if (groupThreadId.x < meshlet.vertexCount)
{
Vertex vertex = data->vertices[meshlet.vertexOffset + groupThreadId.x];
float32x4 position = data->matrixMVP * vertex.position;
// TODO: Normal transform here
outVertices[groupThreadId.x] = { .position = position, .normal = normal, .uv = vertex.uv };
}
}Both vertex shaders and mesh shaders use pixel shaders. Rasterizer spawns pixel shader work based on triangle pixel coverage, HiZ, and early depth/stencil test results. Hardware can pack multiple triangles and multiple instances in the same pixel shader wave. Pixel shaders itself aren’t that special. Nowadays pixel shaders run on the same SIMD cores as all the other shader types. There are some special inputs available: interpolated vertex outputs, screen location, sample index and coverage mask, triangle id, triangle facing, etc. Special inputs are declared as kernel function parameters using the system value (: SV) semantics, similar to existing APIs.
// Pixel shader...
const Texture textureHeap[];
struct VertexIn // Matching vertex shader output struct layout
{
float16x4 normal;
float32x2 uv;
};
struct PixelOut
{
float16x4 color : SV_Color0;
};
PixelOut main(const VertexIn &vertex, const DataPixel* data)
{
Texture texture = textureHeap[data->textureIndex];
Sampler sampler = {.minFilter = LINEAR, .magFilter = LINEAR};
float32x4 color = sample(texture, sampler, vertex.uv);
return { .color = color };
}The removal of data bindings makes vertex and pixel shaders simpler to use. All of the complex data bindings APIs are replaced by a 64-bit GPU pointer. Users are able to write flexible vertex fetch code to avoid creating a PSO permutation per vertex layout.
Rasterizer state
Legacy APIs (OpenGL and DirectX 9) had fine grained commands for setting all the shader inputs and rasterizer states. The driver had to build shader pipelines on demand. Hardware specific rasterizer, blender, and input assembler command packets were constructed from the shadow state that combined all individual fine grained states. Vulkan 1.0 and DirectX 12 chose the fully opposite design. All state is baked in the PSO ahead of time. Only a select few states, such as viewport rect, scissor rect, and stencil values, can be changed dynamically. This resulted in a massive explosion of PSO permutations.
PSO creation is expensive, as it requires calling the GPU driver’s low-level shader compiler. PSO permutations consume a significant amount of storage and RAM. Changing the PSO is the most expensive state change. The small performance advantages that some vendors achieved by embedding render state directly into the shader microcode were overshadowed by the performance issues caused by significantly amplified pipeline creation, binding and data management costs everywhere. The pendulum swung too far to the opposite side.
Modern GPUs are ALU dense. Nvidia and AMD recently doubled their ALU rate with additional pipelines. Apple also doubled their fp32 pipelines in their M-series chips. Simple states resulting only in a constant replacement in the shader should not require pipeline duplication, even if it adds an extra ALU instruction or wastes an uniform register. Most shaders today are not ALU bound. The cost is often not measurable, but the benefits of having less permutations are significant. Vulkan 1.3 is a big step in the right direction. A lot of baked PSO states can now be set dynamically.
If we investigate deeper, we notice that all GPUs use command packets for configuring their rasterizer and depth-stencil units. These command packets are not directly tied to the shader microcode. We don’t need to modify the shader microcode to change the rasterizer and depth-stencil state. Metal has a separate depth-stencil state object and a separate command for applying it. A separate state object reduces the PSO permutations and reduces the expensive shader binding calls. Vulkan 1.3 dynamic state achieves similar PSO permutation reduction, but is more fine grained. Metal’s design is a better match for the actual hardware command packets. Bigger packets reduce the API bloat and overhead. DirectX 12 unfortunately still bundles most of the depth-stencil state inside the PSO (stencil ref and depth bias are the only dynamic state). In our design the depth-stencil state is a separate object.
GpuDepthStencilDesc depthStencilDesc =
{
.depthMode = DEPTH_READ | DEPTH_WRITE,
.depthTest = OP_LESS_EQUAL,
.depthBias = 0.0f,
.depthBiasSlopeFactor = 0.0f,
.depthBiasClamp = 0.0f,
.stencilReadMask = 0xff,
.stencilWriteMask = 0xff,
.stencilFront =
{
.test = OP_ALWAYS,
.failOp = OP_KEEP,
.passOp = OP_KEEP,
.depthFailOp = OP_KEEP,
.reference = 0
},
.stencilBack =
{
.test = COMPARE_ALWAYS,
.failOp = OP_KEEP,
.passOp = OP_KEEP,
.depthFailOp = OP_KEEP,
.reference = 0
}
};
// A minimal way to descibe the above (using C++ API struct default values):
GpuDepthStencilDesc depthStencilDesc =
{
.depthMode = DEPTH_READ | DEPTH_WRITE,
.depthTest = OP_LESS_EQUAL,
};
GpuDepthStencilState depthStencilState = gpuCreateDepthStencilState(depthStencilDesc);Immediate mode (desktop) GPUs have similar command packets for configuring the alpha blender unit. If we were designing DirectX 13, we would simply split the blend state object out of the PSO and call it a day. But we are designing a cross platform API, and blending works completely differently on mobile GPUs.
Mobile GPUs (TBDR) have always supported programmable blending. A render tile fits into a scratchpad memory close to the compute unit (such as the groupshared memory), allowing pixel shaders a direct low latency read+write access to previously rasterized pixels. Most mobile GPUs don’t have any fixed function blending hardware. When a traditional graphics API is used, the driver's low level shader compiler adds blending instructions at the end of the shader. This is analogous to the vertex fetch code generation (described above). If we were designing an API solely for mobile GPUs, we would get rid of the blend state APIs completely, just like we got rid of the vertex buffers. Mobile centric APIs expose a framebuffer fetch intrinsic to efficiently obtain current pixel’s previous color. The user can write any blending formula they want, including complex formulas to implement advanced algorithms such as order independent transparency. The user can also write a generic parametrised formula to eliminate the PSO permutation explosion. As we can see, both the desktop and the mobile GPUs have their own ways to reduce the pipeline permutations regarding blending, the limitation is the current APIs.
Vulkan subpasses were designed to wrap framebuffer fetch into a cross platform API. This was another misstep in Vulkan design. Vulkan inherited a simple low level design from Mantle, but Vulkan was designed as an OpenGL replacement, so it had to target all mobile and desktop GPU architectures. Wrapping two entirely different architecture types under the same API isn’t easy. Subpasses ended up being a high level concept inside a low level API. A subpass could define an entire chain of render passes but pretend that it’s just a single render pass. Subpasses increased driver complexity and made the shader and renderpass APIs needlessly complex. Users were forced to create complex persistent multi-render pass objects ahead of time and pass those objects into shader pipeline creation. Shader pipelines became multi-pipelines under the hood (one pipeline per sub-pass). Vulkan added all of this complexity simply to avoid exposing the framebuffer fetch intrinsic to the shader language. To add insult to injury, the subpasses weren’t even good enough to solve the programmable blending. Pixel ordering is only preserved at pass boundaries. Subpasses were only useful for narrow 1:1 multi-pass use cases. Vulkan 1.3 scrapped the subpasses and introduced “dynamic rendering”. Users no longer need to create persistent render pass objects, just like in Metal, DirectX 12 and WebGPU. This is a great example of how a complex framework can be tempting for API designers, but developers prefer simple shader intrinsics. Game engines already support building different shaders to different platforms. Apple’s Metal examples do the same: Framebuffer fetch is used on iOS and a traditional multipass algorithm on Mac.
It’s apparent that we can’t abstract hardware differences regarding blending and framebuffer fetch. Vulkan 1.0 tried that and failed miserably. The correct solution is to provide the user a choice. They can choose to embed the blend state into the PSO. This works on all platforms and is the perfect approach for shaders that don’t suffer from blend state related pipeline permutation issues. Mobile GPU’s internal driver shader compiler adds the blending instructions in the end of the pixel shader as usual. On immediate mode (desktop) GPUs (and some mobile GPUs), the user can choose to use separate blend state objects. This reduces the amount of PSO permutations and makes it faster to change the blend state at runtime, as a full pipeline change is not needed (only a blend state configuration packet is sent).
GpuBlendDesc blendDesc =
{
.colorOp = OP_ONE,
.srcColorFactor = FACTOR_SRC_ALPHA,
.dstColorFactor = FACTOR_ONE_MINUS_SRC_ALPHA,
.alphaOp = OP_ONE,
.srcAlphaFactor = FACTOR_SRC_ALPHA,
.dstAlphaFactor = FACTOR_ONE_MINUS_SRC_ALPHA,
.colorWriteMask = 0xf
};
// Create blend state object (needs feature flag)
GpuBlendState blendState = gpuCreateBlendState(blendDesc);
// Set dynamic blend state (needs feature flag)
gpuSetBlendState(commandBuffer, blendState);On mobile GPUs the user can embed the blend state into the PSO as usual, or choose to use framebuffer fetch to write a custom blending formula. If the mobile developer wants to avoid compiling multiple PSO permutations for different alpha blending modes, they can write a general formula parametrized with dynamic draw struct inputs.
// Standard percentage blend formula (added automatically by internal shader compiler)
dst.rgb = src.rgb * src.a + dst.rgb * (1.0 - src.a);
dst.a = src.a * src.a + dst.a * (1.0 - src.a);
// Custom formula supporting all blend modes used by HypeHype
const BlendParameters& p = data->blendParameters;
vec4 fs = src.a * vec4(p.sc_sa.xxx + p.sc_one.xxx, p.sa_sa + p.sa_one) + dst.rgba * vec4(p.sc_dc.xxx, sa_da);
vec4 fd = (1.0 - src.a) * vec4(p.dc_1msa.xxx, p.da_1msa) + vec4(p.dc_one.xxx, p.da_one);
dst.rgb = src.rgb * fs.rgb + dst.rgb * fd.rgb;
dst.a = src.a * fs.a + dst.a * fd.a;As the blend state is separated from the PSO, it’s possible we lose some automatic dead code optimizations. If the user wants to disable the color output, they traditionally use the colorWriteMask in the blend state. Since the blend state is burned in the PSO, the compiler can do dead code elimination based on it. To allow similar dead code optimizations, we have writeMask for each color target in the PSO.
Dual source blending is a special blend mode requiring two color outputs from the pixel shader. Dual source blending only supports a single render target. Since our blend state can be separate, we need to have a supportDualSourceBlending field in our PSO desc. When enabled, the shader compiler knows the second output is for dual source blending. The validation layer would complain if the output is not present. A pixel shader exporting two colors can be used without dual source blending (the second color is ignored), but there’s a small cost for exporting two colors.
The remaining rendering state in the PSO is minimal: primitive topology, render target and depth-stencil target formats, MSAA sample count and alpha to coverage. All of this state affects the generated shader microcode so it needs to stay in the PSO. We never want to rebuild the shader PSO microcode due to a state change. If an embedded blend state is used, it's also burned in the PSO. This leaves us with a simple raster state struct for PSO creation.
GpuRasterDesc rasterDesc =
{
.topology = TOPOLOGY_TRIANGLE_LIST,
.cull = CULL_CCW,
.alphaToCoverage = false,
.supportDualSourceBlending = false,
.sampleCount = 1`
.depthFormat = FORMAT_D32_FLOAT,
.stencilFormat = FORMAT_NONE,
.colorTargets =
{
{ .format = FORMAT_RG11B10_FLOAT }, // G-buffer with 3 render targets
{ .format = FORMAT_RGB10_A2_UNORM },
{ .format = FORMAT_RGBA8_UNORM }
},
.blendstate = GpuBlendDesc { ... } // optional (embedded blend state, otherwise dynamic)
};
// A minimal way to descibe the above (using C++ API struct default values):
GpuRasterDesc rasterDesc =
{
.depthFormat = FORMAT_D32_FLOAT,
.colorTargets =
{
{ .format = FORMAT_RG11B10_FLOAT },
{ .format = FORMAT_RGB10_A2_UNORM },
{ .format = FORMAT_RGBA8_UNORM }
},
};
// Pixel + vertex shader
auto vertexIR = loadFile("vertexShader.ir");
auto pixelIR = loadFile("pixelShader.ir");
GpuPipeline graphicsPipeline = gpuCreateGraphicsPipeline(vertexIR, pixelIR, rasterDesc);
// Mesh shader
auto meshletIR = loadFile("meshShader.ir");
auto pixelIR = loadFile("pixelShader.ir");
GpuPipeline graphicsMeshletPipeline = gpuCreateGraphicsMeshletPipeline(meshletIR, pixelIR, rasterDesc);HypeHype’s Vulkan shader PSO initialization backend code is 400 lines, and I would consider it compact compared to other engines I have been developing. Here, we managed to initialize a pixel + vertex shader with just 18 lines of code. It’s easy to read and understand. Yet, there’s no compromise on performance.
Rendering with the raster pipeline is similar to rendering with a compute pipeline. Instead of providing one data pointer, we provide two since there’s two kernel entry points: One for vertex shader and one for pixel shader. Metal has a separate set of data binding slots for vertex and pixel shaders. DirectX, Vulkan and WebGPU use a visibility mask (vertex, pixel, compute, etc) for each individual binding. Many engines choose to bind the same data to both vertex and pixel shader. This is a fine practice on DirectX, Vulkan and WebGPU as you can combine the mask bits, but doubles the binding calls on Metal. Our proposed approach using two data pointers is the best of both worlds. You can simply pass the same pointer twice if you want to use the same data in both the vertex and the pixel shader. Or you can provide independent data pointers, if you prefer full separation between the shader stages. The shader compiler does dead code elimination and constant/scalar preload optimizations separately for pixel and vertex shader. Neither data sharing nor data duplication results in bad performance. The user can choose whatever fits their design.
// Common header...
struct Vertex
{
float32x4 position;
uint16x2 uv;
};
struct alignas(16) DataVertex
{
float32x4x4 matrixMVP;
const Vertex *vertices;
};
struct alignas(16) DataPixel
{
float32x4 color;
uint32 textureIndex;
};
// CPU code...
gpuSetDepthStencilState(commandBuffer, depthStencilState);
gpuSetPipeline(commandBuffer, graphicsPipeline);
auto dataVertex = myBumpAllocator.allocate<DataVertex>();
dataVertex.cpu->matrixMVP = camera.viewProjection * modelMatrix;
dataVertex.cpu->vertices = mesh.vertices;
auto dataPixel = myBumpAllocator.allocate<DataPixel>();
dataPixel.cpu->color = material.color;
dataPixel.cpu->textureIndex = material.textureIndex;
gpuDrawIndexed(commandBuffer, dataVertex.gpu, dataPixel.gpu, mesh.indices, mesh.indexCount);
// Vertex shader...
struct VertexOut
{
float32x4 position : SV_Position; // SV values are not real struct fields (doesn't affect the layout)
float32x2 uv;
};
VertexOut main(uint32 vertexIndex : SV_VertexID, const DataVertex* data)
{
Vertex vertex = data.vertices[vertexIndex];
float32x4 position = data->matrixMVP * vertex.position;
return { .position = position, .uv = vertex.uv };
}
// Pixel shader...
const Texture textureHeap[];
struct VertexIn // Matching vertex shader output struct layout
{
float32x2 uv;
};
PixelOut main(const VertexIn &vertex, const DataPixel* data)
{
Texture texture = textureHeap[data->textureIndex];
Sampler sampler = {.minFilter = LINEAR, .magFilter = LINEAR};
float32x4 color = sample(texture, sampler, vertex.uv);
return { .color = color };
}Our goal was to reduce the PSO permutation explosion by minimizing the remaining state inside the PSO. The depth-stencil can be separated on all architectures. The blend state separation is possible on desktop hardware, but most mobile hardware burns the blend equation at the end of the pixel shader microcode. Exposing the framebuffer fetch intrinsics directly to the user is a much better idea than Vulkan’s failed subpass approach. Users can write their own blend formulas unlocking new rendering algorithms, or they can author general parametrized blending formulas to reduce the PSO count.
Indirect drawing
Standard draw/dispatch commands utilize C/C++ function parameters to provide the arguments: thread group dimensions, index count, instance count, etc. Indirect draw calls allow the user to provide a GPU buffer + offset pair instead as the draw argument source, a crucial addition enabling GPU-driven rendering. Our version uses a single GPU pointer instead of the usual buffer object + offset pair, simplifying the API slightly.
gpuDispatchIndirect(commandBuffer, data.gpu, arguments.gpu);
gpuDrawIndexedInstancedIndirect(commandBuffer, dataVertex.gpu, dataPixel.gpu, arguments.gpu);All of our arguments are GPU pointers. Both the data and the arguments are indirect. This is a great improvement over existing APIs. DirectX 12, Vulkan and Metal don’t support indirect root arguments. The CPU has to provide them.
Indirect multidraw (MDI) should also be supported. The draw count comes from a GPU address. MDI parameters are: an array of root data (GPU pointer, for both vertex and pixel), an array of draw arguments (GPU pointer), and stride for the root data array (for both vertex and pixel). Stride = 0 naturally means that the same root data is replicated for each draw.
gpuDrawIndexedInstancedIndirectMulti(commandBuffer, dataVertex.gpu, sizeof(DataVertex), dataPixel.gpu, sizeof(DataPixel), arguments.gpu, drawCount.gpu);Vulkan’s multidraw doesn’t allow changing bindings per draw call. You can use gl_DrawID to index into a buffer which contains your draw data structs. This adds an indirection in the shader. You need to use either descriptor indexing or the new descriptor buffer extension to fetch textures. DirectX 12 ExecuteIndirect has a configurable command signature, allowing the user to manually setup a root constant per draw, but this doesn’t hit the fast path on all GPU command processors. ExecuteIndirect tier 1.1 (2024) added a new optional counter increment feature: D3D12_INDIRECT_ARGUMENT_TYPE_INCREMENTING_CONSTANT. This can be used to implement draw ID. SM6.8 (2024) finally added support for SV_StartInstanceLocation, allowing the user to directly embed a constant in the indirect draw arguments. Unlike SV_InstanceID, the new SV_StartInstanceLocation is uniform across the whole draw call, providing optimal codegen for indexed loads (uniform/scalar path). The data fetch still requires an indirection. GPU-generated root data is not supported.
If we generate draw arguments or root data on the GPU, we need to ensure that the command processor waits for the dispatch to finish. Modern command processors prefetch commands and their arguments to hide the latency. We have a flag in our barrier to prevent this. The best practice is to batch update all your draw arguments and root data to avoid fine-grained barriers.
gpuBarrier(commandBuffer, STAGE_COMPUTE, STAGE_COMPUTE, HAZARD_DRAW_ARGUMENTS);The lack of indirect shader selection is a significant limitation in the current PC and mobile graphics APIs. Indirect shader selection can be implemented using multi-pipelines similar to ray-tracing. Metal also supports indirect command creation (Nvidia has a similar Vulkan extension). An efficient way to skip over draw calls is a valuable subset. DirectX work graphs and CUDA dynamic parallelism allow a shader to spawn more waves on demand. Unfortunately, the APIs to access these hardware improvements is still highly platform specific and scattered in multiple shader entry points. There’s no clear standardization. My followup post will discuss the shader framework and cover this topic in depth.
Our proposed design makes indirect drawing extremely powerful. Both the shader root data and the draw parameters can be indirectly provided by the GPU. These advantages power up multi-draw, allowing clean and efficient per-draw data bindings with no hacks. The future of indirect drawing and the shader framework will be discussed in a followup post.
Render passes
The rasterizer hardware needs to be prepared for rendering before we can start drawing. Common operations include binding render target and depth-stencil views and clearing color and depth. Clear might trigger a fast clear elimination if the clear color is changed. This is transparently handled by the clear command. On mobile GPUs, tiles are stored from on-chip storage to VRAM during rendering. Vulkan, Metal and WebGPU use render pass abstraction for clearing, loading and storing the render target. DirectX 12 added render pass support in the 2018 update in order to optimize rendering on the latest Intel (Gen11) and the Qualcomm (Adreno 630) GPUs. The render pass abstraction doesn’t add notable API complexity, so it's an easy choice for a modern cross platform API.
DirectX12 has render target views and depth-stencil views, and separate descriptor heaps to store them. This is just an API abstraction. These heaps are simply CPU memory allocated by the driver. Render target and depth-stencil views are not GPU descriptors. The rasterizer API is not bindless. The CPU driver sets up the rasterizer using command packets. In Vulkan and Metal you pass the existing texture/view objects to the beginRenderPass directly. The driver gets the required information from the texture object behind the scenes. Our proposed GpuTexture object fits this job. Rasterization output is the main reason we still need a CPU-side texture object. We write texture descriptors directly into GPU memory. The CPU side driver can’t access those.
GpuRenderPassDesc renderPassDesc =
{
.depthTarget = {.texture = deptStencilTexture, .loadOp = CLEAR, .storeOp = DONT_CARE, .clearValue = 1.0f},
.stencilTarget = {.texture = deptStencilTexture, .loadOp = CLEAR, .storeOp = DONT_CARE, .clearValue = 0},
.colorTargets =
{
{.texture = gBufferColor, .loadOp = LOAD, .storeOp = STORE, .clearColor = {0,0,0,0}},
{.texture = gBufferNormal, .loadOp = LOAD, .storeOp = STORE, .clearColor = {0,0,0,0}},
{.texture = gBufferPBR, .loadOp = LOAD, .storeOp = STORE, .clearColor = {0,0,0,0}}
}
};
gpuBeginRenderPass(commandBuffer, renderPassDesc);
// Add draw calls here!
gpuEndRenderPass(commandBuffer);It would be nice to have bindless render passes, bindless/indirect (multi-)clear commands, indirect scissor/viewport rectangles (array), etc. Unfortunately many GPUs today still need the CPU driver to set up their rasterizer.
A note about barriers: Render pass begin/end commands don’t automatically emit barriers. The user can render multiple render passes simultaneously, if they write to disjoint render targets. A barrier between the raster output stage (or later) and the consumer stage will flush the tiny ROP caches if the GPU architecture needs it. Not having an automatic barrier between the render passes is also crucial for efficient depth prepass implementations (ROP caches are not flushed needlessly).

GPU-based clay simulation and ray-tracing tech in Claybook (Sebastian Aaltonen, GDC 2018): I optimized the Unreal Engine 4 console barrier implementations (Xbox One, PS4) to allow render target overlap. The barrier stall is avoided.
Prototype API
My prototype API fits in one screen: 150 lines of code. The blog post is titled “No Graphics API”. That’s obviously an impossible goal today, but we got close enough. WebGPU has a smaller feature set and features a ~2700 line API (Emscripten C header). Vulkan header is ~20,000 lines, but it supports ray-tracing, and many other features our minimalistic API doesn’t yet support. We didn’t have to trade off performance to achieve the reduction in API complexity. For this feature set, our API offers more flexibility than existing APIs. A fully extended summer 2025 Vulkan 1.4 can do all the same things in practice, but is significantly more complex to use and has more API overhead.
// Opaque handles
struct GpuPipeline;
struct GpuTexture;
struct GpuDepthStencilState;
struct GpuBlendState;
struct GpuQueue;
struct GpuCommandBuffer;
struct GpuSemaphore;
// Enums
enum MEMORY { MEMORY_DEFAULT, MEMORY_GPU, MEMORY_READBACK };
enum CULL { CULL_CCW, CULL_CW, CULL_ALL, CULL_NONE };
enum DEPTH_FLAGS { DEPTH_READ = 0x1, DEPTH_WRITE = 0x2 };
enum OP { OP_NEVER, OP_LESS, OP_EQUAL, OP_LESS_EQUAL, OP_GREATER, OP_NOT_EQUAL, OP_GREATER_EQUAL, OP_ALWAYS };
enum BLEND { BLEND_ADD, BLEND_SUBTRACT, BLEND_REV_SUBTRACT, BLEND_MIN, BLEND_MAX };
enum FACTOR { FACTOR_ZERO, FACTOR_ONE, FACTOR_SRC_COLOR, FACTOR_DST_COLOR, FACTOR_SRC_ALPHA, ... };
enum TOPOLOGY { TOPOLOGY_TRIANGLE_LIST, TOPOLOGY_TRIANGLE_STRIP, TOPOLOGY_TRIANGLE_FAN };
enum TEXTURE { TEXTURE_1D, TEXTURE_2D, TEXTURE_3D, TEXTURE_CUBE, TEXTURE_2D_ARRAY, TEXTURE_CUBE_ARRAY };
enum FORMAT { FORMAT_NONE, FORMAT_RGBA8_UNORM, FORMAT_D32_FLOAT, FORMAT_RG11B10_FLOAT, FORMAT_RGB10_A2_UNORM, ... };
enum USAGE_FLAGS { USAGE_SAMPLED, USAGE_STORAGE, USAGE_COLOR_ATTACHMENT, USAGE_DEPTH_STENCIL_ATTACHMENT, ... };
enum STAGE { STAGE_TRANSFER, STAGE_COMPUTE, STAGE_RASTER_COLOR_OUT, STAGE_PIXEL_SHADER, STAGE_VERTEX_SHADER, ... };
enum HAZARD_FLAGS { HAZARD_DRAW_ARGUMENTS = 0x1, HAZARD_DESCRIPTORS = 0x2, , HAZARD_DEPTH_STENCIL = 0x4 };
enum SIGNAL { SIGNAL_ATOMIC_SET, SIGNAL_ATOMIC_MAX, SIGNAL_ATOMIC_OR, ... };
// Structs
struct Stencil
{
OP test = OP_ALWAYS,
OP failOp = OP_KEEP;
OP passOp = OP_KEEP;
OP depthFailOp = OP_KEEP;
uint8 reference = 0;
};
struct GpuDepthStencilDesc
{
DEPTH_FLAGS depthMode = 0;
OP depthTest = OP_ALWAYS;
float depthBias = 0.0f;
float depthBiasSlopeFactor = 0.0f;
float depthBiasClamp = 0.0f;
uint8 stencilReadMask = 0xff;
uint8 stencilWriteMask = 0xff;
Stencil stencilFront;
Stencil stencilBack;
};
struct GpuBlendDesc
{
BLEND colorOp = BLEND_ADD,
FACTOR srcColorFactor = FACTOR_ONE;
FACTOR dstColorFactor = FACTOR_ZERO;
BLEND alphaOp = BLEND_ADD;
FACTOR srcAlphaFactor = FACTOR_ONE;
FACTOR dstAlphaFactor = FACTOR_ZERO;
uint8 colorWriteMask = 0xf;
};
struct ColorTarget {
FORMAT format = FORMAT_NONE;
uint8 writeMask = 0xf;
};
struct GpuRasterDesc
{
TOPOLOGY topology = TOPOLOGY_TRIANGLE_LIST;
CULL cull = CULL_NONE;
bool alphaToCoverage = false;
bool supportDualSourceBlending = false;
uint8 sampleCount = 1;
FORMAT depthFormat = FORMAT_NONE;
FORMAT stencilFormat = FORMAT_NONE;
Span<ColorTarget> colorTargets = {};
GpuBlendDesc* blendstate = nullptr; // optional embedded blend state
};
struct GpuTextureDesc
{
TEXTURE type = TEXTURE_2D;
uint32x3 dimensions;
uint32 mipCount = 1;
uint32 layerCount = 1;
uint32 sampleCount = 1;
FORMAT format = FORMAT_NONE;
USAGE_FLAGS usage = 0;
};
struct GpuViewDesc
{
FORMAT format = FORMAT_NONE;
uint8 baseMip = 0;
uint8 mipCount = ALL_MIPS;
uint16 baseLayer = 0;
uint16 layerCount = ALL_LAYERS;
};
struct GpuTextureSizeAlign { size_t size; size_t align; };
struct GpuTextureDescriptor { uint64[4] data; };
// Memory
void* gpuMalloc(size_t bytes, MEMORY memory = MEMORY_DEFAULT);
void* gpuMalloc(size_t bytes, size_t align, MEMORY memory = MEMORY_DEFAULT);
void gpuFree(void *ptr);
void* gpuHostToDevicePointer(void *ptr);
// Textures
GpuTextureSizeAlign gpuTextureSizeAlign(GpuTextureDesc desc);
GpuTexture gpuCreateTexture(GpuTextureDesc desc, void* ptrGpu);
GpuTextureDescriptor gpuTextureViewDescriptor(GpuTexture texture, GpuViewDesc desc);
GpuTextureDescriptor gpuRWTextureViewDescriptor(GpuTexture texture, GpuViewDesc desc);
// Pipelines
GpuPipeline gpuCreateComputePipeline(ByteSpan computeIR);
GpuPipeline gpuCreateGraphicsPipeline(ByteSpan vertexIR, ByteSpan pixelIR, GpuRasterDesc desc);
GpuPipeline gpuCreateGraphicsMeshletPipeline(ByteSpan meshletIR, ByteSpan pixelIR, GpuRasterDesc desc);
void gpuFreePipeline(GpuPipeline pipeline);
// State objects
GpuDepthStencilState gpuCreateDepthStencilState(GpuDepthStencilDesc desc);
GpuBlendState gpuCreateBlendState(GpuBlendDesc desc);
void gpuFreeDepthStencilState(GpuDepthStencilState state);
void gpuFreeBlendState(GpuBlendState state);
// Queue
GpuQueue gpuCreateQueue(/* DEVICE & QUEUE CREATION DETAILS OMITTED */);
GpuCommandBuffer gpuStartCommandRecording(GpuQueue queue);
void gpuSubmit(GpuQueue queue, Span<GpuCommandBuffer> commandBuffers);
// Semaphores
GpuSemaphore gpuCreateSemaphore(uint64 initValue);
void gpuWaitSemaphore(GpuSemaphore sema, uint64 value);
void gpuDestroySemaphore(GpuSemaphore sema);
// Commands
void gpuMemCpy(GpuCommandBuffer cb, void* destGpu, void* srcGpu,);
void gpuCopyToTexture(GpuCommandBuffer cb, void* destGpu, void* srcGpu, GpuTexture texture);
void gpuCopyFromTexture(GpuCommandBuffer cb, void* destGpu, void* srcGpu, GpuTexture texture);
void gpuSetActiveTextureHeapPtr(GpuCommandBuffer cb, void *ptrGpu);
void gpuBarrier(GpuCommandBuffer cb, STAGE before, STAGE after, HAZARD_FLAGS hazards = 0);
void gpuSignalAfter(GpuCommandBuffer cb, STAGE before, void *ptrGpu, uint64 value, SIGNAL signal);
void gpuWaitBefore(GpuCommandBuffer cb, STAGE after, void *ptrGpu, uint64 value, OP op, HAZARD_FLAGS hazards = 0, uint64 mask = ~0);
void gpuSetPipeline(GpuCommandBuffer cb, GpuPipeline pipeline);
void gpuSetDepthStencilState(GpuCommandBuffer cb, GpuDepthStencilState state);
void gpuSetBlendState(GpuCommandBuffer cb, GpuBlendState state);
void gpuDispatch(GpuCommandBuffer cb, void* dataGpu, uvec3 gridDimensions);
void gpuDispatchIndirect(GpuCommandBuffer cb, void* dataGpu, void* gridDimensionsGpu);
void gpuBeginRenderPass(GpuCommandBuffer cb, GpuRenderPassDesc desc);
void gpuEndRenderPass(GpuCommandBuffer cb);
void gpuDrawIndexedInstanced(GpuCommandBuffer cb, void* vertexDataGpu, void* pixelDataGpu, void* indicesGpu, uint32 indexCount, uint32 instanceCount);
void gpuDrawIndexedInstancedIndirect(GpuCommandBuffer cb, void* vertexDataGpu, void* pixelDataGpu, void* indicesGpu, void* argsGpu);
void gpuDrawIndexedInstancedIndirectMulti(GpuCommandBuffer cb, void* dataVxGpu, uint32 vxStride, void* dataPxGpu, uint32 pxStride, void* argsGpu, void* drawCountGpu);
void gpuDrawMeshlets(GpuCommandBuffer cb, void* meshletDataGpu, void* pixelDataGpu, uvec3 dim);
void gpuDrawMeshletsIndirect(GpuCommandBuffer cb, void* meshletDataGpu, void* pixelDataGpu, void *dimGpu);Tooling
How can we debug code that doesn’t bind buffer and texture objects and doesn’t call an API to describe the memory layout explicitly? C/C++ debuggers have been doing that for decades. There’s no special operating system APIs for describing your software’s memory layout. The debugger is able to follow 64-bit pointer chains and use the debug symbol data provided by your compiler. This includes the memory layouts of your structs and classes. CUDA and Metal use C/C++ based shading languages with full 64-bit pointer semantics. Both have robust debuggers that traverse pointer chains without issues. The texture descriptor heap is just GPU memory. The debugger can index it, load a texture descriptor, show the descriptor data and visualize the texels. All of this works already in the Xcode Metal debugger. Click on a texture or a sampler handle in any struct in any GPU address. Debugger will visualize it.
Modern GPUs virtualize memory. Each process has their own page table. The GPU capture has a separate replayer process with its own virtual address space. If the replayer would naively replay all the allocations, it would get a different GPU virtual address for each memory allocation. This was fine for legacy APIs as it wasn’t possible to directly store GPU addresses in your data structures. A modern API needs special replay memory allocation APIs that force the replayer to mirror the exact GPU virtual memory layout. DX12 and Vulkan BDA have public APIs for this: RecreateAt and VkMemoryOpaqueCaptureAddressAllocateInfo. Metal and CUDA debuggers do the same using internal undocumented APIs. A public API is preferable as it allows open source tools like RenderDoc to function.
Don’t raw pointers bring security concerns? Can’t you just read/write other apps' memory? This is not possible due to virtual memory. You can only access your own memory pages. If you accidentally use a stale pointer or overflow, you will get a page fault. Page faults are possible with existing buffer based APIs. DirectX 12 and Vulkan don’t clamp your storage (byteaddress/structured) buffer addresses. OOB causes a page fault. Users can also accidentally free a memory heap and continue using stale buffer or texture descriptors to get a page fault. Nothing really changes. An access to an unmapped region is a page fault and the application crashes. This is familiar to C/C++ programmers. If you want robustness, you can use ptr + size pairs. That’s exactly how WebGPU is implemented. The WebGPU shader compiler (Tint or Naga) emits an extra clamp instruction for each buffer access, including vertex accesses (index buffer value out of bounds). WebGL didn’t allow shading index buffer data with other data. WebGL scanned through the indices on the CPU side (making index buffer update very slow). Back then custom vertex fetch was not possible. The hardware page faulted before the shader even ran.
Translation layers
Being able to run existing software is crucial. Translation layers such as ANGLE, Proton and MoltenVK play a crucial role in the portability and deprecation process of legacy APIs. Let’s talk about translating DirectX 12, Vulkan and Metal to our new API.
MoltenVK (Vulkan to Metal translation layer) proves that Vulkan’s buffer centric API can be translated to Metal’s 64-bit pointer based ecosystem. MoltenVK translates Vulkan’s descriptor sets into Metal’s argument buffers. The generated argument buffers are standard GPU structs containing a 64-bit GPU pointer per buffer binding and a 64-bit texture ID per texture binding. We can do better by allocating a contiguous range of texture descriptors in our texture heap for each descriptor set, and storing a single 32-bit base index instead of a 64-bit texture ID for each texture binding. This is possible since our API has a user managed texture heap unlike Metal.
MoltenVK maps descriptor sets to Metal API root bind slots. We generate a root struct with up to eight 64-bit pointer fields, each pointing to a descriptor set struct (see above). Root constants are translated into value fields and root descriptors (root buffers) are translated into 64-bit pointers. The efficiency should be identical, assuming the GPU driver preloads our root struct fields into uniform/scalar registers (as discussed in the root arguments chapter).
Our API uses 64-bit pointer semantics like Metal. We can use the same techniques employed by MoltenVK to translate the buffer load/store instructions in the shader. MoltenVK also supports translating Vulkan’s new buffer device address extension.
Proton (DX12 to Vulkan translation layer) proves that DirectX 12 SM 6.6 descriptor heap can be translated to Vulkan’s new descriptor buffer extension. Proton also translates other DirectX 12 features to Vulkan. We have already shown that Vulkan to Metal translation is possible with MoltenVK, transitively proving that translation from DirectX 12 to Metal should be possible. The biggest missing feature in MoltenVK is the SM 6.6 style descriptor heap (Vulkan’s descriptor buffer extension). Metal doesn’t expose the descriptor heap directly to the user. Our new proposed API has no such limitation. Our descriptor heap semantics are a superset to SM 6.6 descriptor heap and a close match to Vulkan’s descriptor buffer extension. Translation is straightforward. Vulkan’s extension also adds a special flag for descriptor invalidate, matching our HAZARD_DESCRIPTORS. DirectX 12 descriptor heap API is easy to translate, as it’s just a thin wrapper over the raw descriptor array in GPU memory.
To support Metal 4.0, we need to implement Metal’s driver managed texture descriptor heap. This can be implemented using a simple freelist over our texture heap. Metal uses 64-bit texture handles which are implemented as direct heap indices on modern Apple Silicon devices. Metal allows using the texture handles in shaders directly as textures. This is syntactic sugar for textureHeap[uint64(handle)]. A Metal texture handle is translated into uint64 by our shader translator, maintaining identical GPU memory layout.
Our API doesn’t support vertex buffers. WebGPU doesn’t use hardware vertex buffers either, yet it implements the classic vertex buffer abstraction. WGSL shader translator (Tint or Naga) adds one storage buffer binding per vertex stream and emits vertex load instructions in the beginning of the vertex shader. Custom vertex fetch allows emitting clamp instructions to avoid OOB behavior. A misbehaving website can’t crash the web browser. Our own shader translator adds a 64-bit pointer to the root struct for each vertex stream, generates a struct matching its layout and emits vertex struct load instructions in the beginning of the vertex shader.
We have shown that it’s possible to write translation layers to run DirectX 12, Vulkan and Metal applications on top of our new API. Since WebGPU is implemented on top of these APIs by browsers, we can run WebGPU applications too.
Min spec hardware
Nvidia Turing (RTX 2000 series, 2018) introduced ray-tracing, tensor cores, mesh shaders, low latency raw memory paths, bigger & faster caches, scalar unit, secondary integer pipeline and many other future looking features. Officially PCIe ReBAR support launched with RTX 3000 series, but there exists hacked Turing drivers that support it too, indicating that the hardware is capable of it. This 7 year old GPU supports everything we need. Nvidia just ended GTX 1000 series driver support in fall 2025. All currently supported Nvidia GPUs could be supported by our new API.
AMD RDNA2 (RX 6000 series, 2020) matched Nvidia’s feature set with ray-tracing and mesh shaders. One year earlier, RDNA 1 introduced coherent L2$, new L1$ level, fast L0$, generic DCC read/write paths, fastpath unfiltered loads and a modern SIMD32 architecture. PCIe ReBAR is officially supported (brand name “Smart Access Memory”). This 5 year old GPU supports everything we need. AMD ended GCN driver support already in 2021. Today RDNA 1 & RDNA 2 only receive bug fixes and security updates, RDNA 3 is the oldest GPU receiving game optimizations. All the currently supported AMD GPUs could be supported by our API.
Intel Alchemist / Xe1 (2022) were the first Intel chips with SM 6.6 global indexable heap support. These chips also support ray-tracing, mesh shaders, PCIe ReBAR (discrete) and UMA (integrated). These 3 year old Intel GPUs support everything we need.
Apple M1 / A14 (MacBook M1, iPhone 12, 2020) support Metal 4.0. Metal 4.0 guarantees GPU memory visibility to CPU (UMA on both phones and computers), and allows the user to write 64-bit pointers and 64-bit texture handles directly into GPU memory. Metal 4.0 has a new residency set API, solving a crucial usability issue with bindless resource management in the old useResource/useHeap APIs. iOS 26 still supports iPhone 11. Developers are not allowed to ship apps that require Metal 4.0 just yet. iOS 27 likely deprecates iPhone 11 support next year. On Mac, if you drop Intel Mac support, you have guaranteed Metal 4.0 support. M1-M5 = 5 generations = 5 years.
ARM Mali-G710 (2021) is ARMs first modern architecture. It introduced their new command stream frontend (CSF), reducing the CPU dependency of draw call building and adding crucial features like multi-draw indirect and compute queues. Non-uniform index texture sampling is significantly faster and the AFBC lossless compressor now supports 16-bit floating point targets. G710 supports Vulkan BDA and descriptor buffer extensions and is capable of supporting the new 2025 unified image layout extension with future drivers. The Mali-G715 (2022) introduced support for ray-tracing.
Qualcomm Adreno 650 (2019) supports Vulkan BDA, descriptor buffer and unified image layout extensions, 16-bit storage/math, dynamic rendering and extended dynamic state with the latest Turnip open source drivers. Adreno 740 (2022) introduced support for ray-tracing.
PowerVR DXT (Pixel 10, 2025) is PowerVRs first architecture that supports Vulkan descriptor buffer and buffer device address extensions. It also supports 64-bit atomics, 8-bit and 16-bit storage/math, dynamic rendering, extended dynamic state and all the other features we require.
Conclusion
Modern graphics API have improved gradually in the past 10 years. Six years after DirectX 12 launch, SM 6.6 (2021) introduced the modern global texture heap, allowing fully bindless renderer design. Metal 4.0 (2025) and CUDA have a clean 64-bit pointer based shader architecture with minimal binding API surface. Vulkan has the most restrictive standard, but extensions such as buffer device access (2020), descriptor buffer (2022) and unified image layouts (2025) add support for modern bindless infrastructure, but tools are still lagging behind. As of today, there’s no single API that meets all our requirements, but if we combine their best bits together, we can build the perfect API for modern hardware.
10 years ago, modern APIs were designed for CPU-driven binding models. New bindless features were presented as optional features and extensions. A clean break would improve the usability and reduce the API bloat and driver complexity significantly. It’s extremely difficult to get the whole industry behind a brand new API. I am hoping that vendors are willing to drop backwards compatibility in their new major API versions (Vulkan 2.0, DirectX 13) to embrace the fully bindless GPU architecture we have today. A new bindless API design would solve the mismatch between the API and the game engine RHI, allowing us to get rid of the hash maps and fine grained resource tracking. Metal 4.0 is close to this goal, but it is still missing the global indexable texture heap. A 64-bit texture handle can’t represent a range of textures.
HLSL and GLSL shading languages were designed over 20 years ago as a framework of 1:1 elementwise transform functions (vertex, pixel, geometry, hull, domain, etc). Memory access is abstracted and array handling is cumbersome as there’s no support for pointers. Despite 20 years of existence, HLSL and GLSL have failed to accumulate a library ecosystem. CUDA in contrast is a composable language exposing memory directly and new features (such as AI tensor cores) though intrinsics. CUDA has a broad library ecosystem, which has propelled Nvidia into $4T valuation. We should learn from it.
WebGPU note: WebGPU design is based on 10 year old core Vulkan 1.0 with extra restrictions. WebGPU doesn’t support bindless resources, 64-bit GPU pointers or persistently mapped GPU memory. It feels like a mix between DirectX 11 and Vulkan 1.0. It is a great improvement for web graphics, but doesn’t meet modern bindless API standards. I will discuss WebGPU in a separate blog post.
My prototype API shows what is achievable with modern GPU architectures today, if we mix the best bits from all the latest APIs. It is possible to build an API that is simpler to use than DirectX 11 and Metal 1.0, yet it offers better performance and flexibility than DirectX 12 and Vulkan. We should embrace the modern bindless hardware.
Appendix
A simple user land GPU bump allocator used in all example code. We call gpuHostToDevicePointer once in the temp allocator constructor. We can perform standard pointer arithmetic (such as offset) on GPU pointers. Traditional Vulkan/DX12 buffer APIs require a separate offset. This simplifies the API and user code (ptr vs handle+offset pair). A production ready temp allocator would implement overflow handing (grow, flush, etc).
template<typename T>
struct GPUTempAllocation<T>
{
T* cpu;
T* gpu;
}
struct GPUBumpAllocator
{
uint8 *cpu;
uint8 *gpu;
uint32 offset = 0;
uint32 size;
TempBumpAllocator(uint32 size) : size(size)
{
cpu = gpuMalloc(size);
gpu = gpuHostToDevicePointer(cpu);
}
TempAllocation<uint8> alloc(int bytes, int align = 16)
{
offset = alignRoundUp(offset, align);
if (offset + bytes > size) offset = 0; // Simple ring wrap (no overflow detection)
TempAllocation<uint8> alloc = { .cpu = cpu + offset, . gpu = gpu + offset };
offset += bytes;
return alloc;
}
template<typename T>
T* alloc(int count = 1)
{
TempAllocation<uint8> mem = alloc(sizeof(T) * count, alignof(T));
return TempAllocation<T> { .cpu = (T*)mem.cpu, . gpu = (T*)mem.gpu };
}
};